Professur Graphische Datenverarbeitung und Visualisierung
Themenpool studentische Arbeiten
Themenpool studentische Arbeiten

Viele Studierende und Beschäftigte der TU Chemnitz beteiligten sich am Christopher Street Day (CSD) in Chemnitz und setzten als TUC-Familie gemeinsam ein Zeichen für Vielfalt, Toleranz und ein diskriminierungsfreies Miteinander …
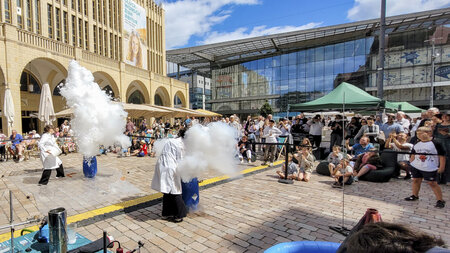
Mit ihrem neuen Programmformat „Dein Start in die Sommerferien mit der TU Chemnitz“ sorgte die Universität am 3. Juli 2026 in der Chemnitzer City für einen etwas anderen letzten Schultag …

Verlängerte Öffnungszeiten, Sonntagsöffnung und weitere buchbare Gruppenarbeitsräume in der Universitätsbibliothek während der Prüfungsperiode vom 6. Juli bis zum 15. August 2026 …

Let´s graduate #TUCgether: Rund 350 Absolventinnen und Absolventen sowie 13 Promovierte der TU Chemnitz wurden am 27. Juni 2026 feierlich verabschiedet und erhielten ihre Graduiertenurkunden in der Chemnitzer St. Petrikirche – Je kühler der Abend, desto stimmungsvoller wurde die TUCsommernacht …
Der Vortrag beleuchtet die Aufgaben aus dem Bundesnaturschutzgesetz als …
Diese Vorlesung bereitet internationale Studierende auf kulturelle und …
Kannst du dir vorstellen, dass Autos in Zukunft ganz allein fahren? In …
Traditionsgemäß werden jedes Jahr zum Beginn des Wintersemesters die neuen …
Stimmen Sie sich mit uns bei einem weihnachtlichen Programm für Groß und Klein auf die Advents- und …
