Handlungsselektion
Teammitglied: Helge Dinkelbach
Mitarbeiter an der Professur künstliche Intelligenz
Im Projekt kurz „The Smart Virtual Worker“ wird ein Werkzeug für die Simulation und Evaluation von Arbeitsprozessen entwickelt. Die Erstellung einer solchen Simulation erfordert einen hohen Arbeitsaufwand und Expertenwissen. Neben der reinen Erstellung des Arbeitsplatzes, werden viele Details des zu simulierenden Arbeitsprozesses benötigt. Der Anwender muss detailliert angeben, welche Werkzeuge bzw. -stücke mit dem Prozess verknüpft sind und er muss Teilprozesse zeitlich ordnen.
Basierend auf den genannten Randbedingungen soll der virtuelle Arbeiter selbständig eine optimale Handlungsabfolge für eine gestellte Aufgabe erlernen. Optimierungskriterien können dabei sowohl eine ergonomische als auch emotionale Bewertung sein. Dabei wird auf Algorithmen des selbstverstärkenden Lernens (Reinforcement Learning [1]) zurückgegriffen um den virtuellen Arbeiter mit einer intelligenten Handlungsselektion auszustatten.
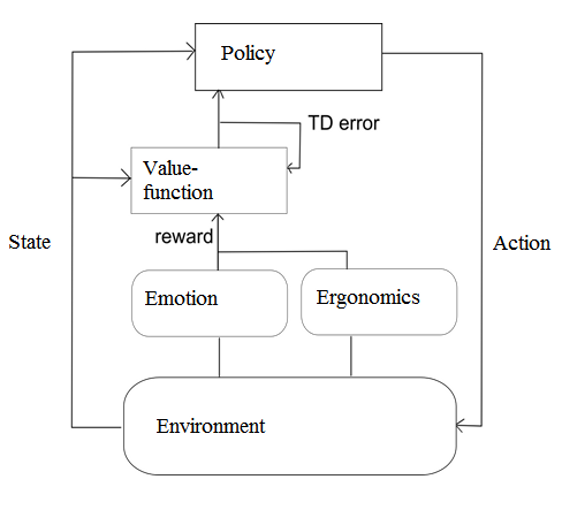
Reinforcement Learning (RL)Ein wesentlicher Vorteil der RL-Algorithmen besteht in der Tatsache, dass keine vollständige Definition des Umweltwissens vorliegen muss. Einer der im Projekt realisierten Agenten basiert auf dem Verfahren des temporal difference (TD) Lernen [1]. Der Agent selektiert eine Handlung anhand einer Strategie (Policy). Nach deren Ausführung wird die erhaltene Belohnung mit der erwarteten Belohnung abgeglichen und ein Fehlersignal (TD error) generiert, anhand dessen die Strategie angepasst wird (vgl. Abb. 1). Typischerweise spiegelt dieses Belohnungssignal die Nähe zum Ziel wieder, ist damit nur von dem erreichen der Aufgabe abhängig. Im Projekt wird dieses Signal um eine ergonomische und emotionale Bewertung erweitert.
|
Abb. 1: Schematische Darstellung des TD Algorithmus, die Belohnung besteht aus einer emotionalen und ergonomischen Bewertung der Aktion (Darstellung: in Anlehung an Sutton u. Barto, 1998, Abbildung 6.15, s. 151) |
Material:
[1] Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction (Vol. 1, No. 1). Cambridge: MIT press.
[2] Papudesi, V., & Huber, M. (2006). Learning behaviorally grounded state representations for reinforcement learning agents. In Prodeedings of the Sixth International Conference on Epigenetic Robotics, Paris, France.
[3] Oladell, M., & Huber, M. (2012, May). Symbol Generation and Grounding for Reinforcement Learning Agents Using Affordances and Dictionary Compression. In Twenty-Fifth International FLAIRS Conference.
[4] Hengst, B. (2007). Safe state abstraction and reusable continuing subtasks in hierarchical reinforcement learning. AI'07 Proceedings of the 20th Australian joint conference on Advances in artificial intelligence. pp 58-67.




