Deep Learning
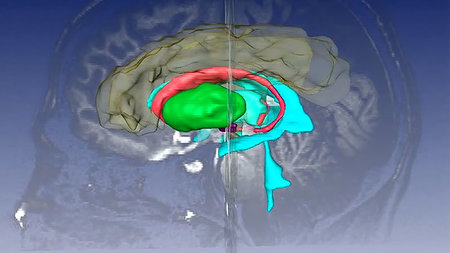
Projektstart für deutsch-israelisch-amerikanisches Kooperationsprojekt zur Erforschung von Tourette- Ursachen …

Oliver Maith, der in Chemnitz Sensorik und kognitive Psychologie studierte, war in einem wettbewerblichen Verfahren zur Promotionsförderung erfolgreich und forscht nun im Bereich der Computational Neuroscience …

TU Chemnitz beteiligt sich an BMBF-gefördertem Projekt zu selbstlernendem Algorithmus für verbesserte Karosseriefertigung …

Orientierungsphase vom 7. bis 11. Oktober 2024 soll Erstsemester der TU Chemnitz bei ihrem Studienstart mit zahlreichen Veranstaltungen und Informationsangeboten unterstützen …
Nach den Landtagswahlen ist vor den Bundestagswahlen. Die Veranstaltung …
Auf Initiative der VHS Zwickau geht die Vortragsreihe "Kulturgut …
Themenschwerpunkte: - Kooperationen und Netzwerke - Ressourceneffiziente Prozesse - …
Wer sich kurzfristig noch für ein Studium an der TU Chemnitz entscheiden …
An den Campustagen können Schüler:innen in den Herbstferien den …
Traditionsgemäß werden jedes Jahr zum Beginn des Wintersemesters die neuen …
