4. Pandas DataFrames#
Im vorherigen Abschnitt Einführung in das Arbeiten mit NumPy haben wir bereits Vektoren und Matrizen und deren Handling, welches breiten Anwendungsbereich findet, in Python kennengelernt. Allerdings benötigt man für statistische Analysen häufig weitere Datenstrukturen, die über die klassischen numerischen Anwendungen hinaus gehen. Das Pandas Paket (Pandas = Python Data Analysis Library) liefert neben Serien vor allem DataFrames, welche Daten in Tabellenform, ähnlich wie in Excel oder SQL zusammenfassen und setzt auf der NumPy-Bibliothek auf. DataFrames haben
Spaltennamen, einen Zeilenindex und erlauben insbesondere in verschiedenen Spalten gemischte Datentypen (int, float, string, usw), was in Datenmatrizen nicht variiert werden kann. Bei Datenanalysen müssen häufig neue Variablen erstellt werden oder Daten in ihrer Struktur angepasst oder zusammengefasst werden. Hierfür bietet Pandas zahlreiche hilfreiche Funktionen. Außerdem stellt Pandas Routinen zum Importieren und Exportieren von CSV-Daten sowie zur Erstellung typischer Graphiken rund um die Datenanalyse bereit, da Pandas ebenso auf dem Paket Matplotlib aufsetzte, welches wir im Abschnitt Erstellung von Grafiken mittels Matplotlib, Seaborn und Plotly noch näher betrachten werden.
All diese Schritte der Datenaufbereitung (Datenimport, Datenbereinigung, Anpassen der Datentypen, Datentransformation, Zusammenfassen verschiedener Datensätze, Aufbereitung für verschiedene statische Anaylsen oder Optimierungsroutinen) fasst man unter dem Begriff Data Wrangling zusammen. Dieser sehr aufwendige Prozess umfasst ca. 80 Prozent der Arbeitszeit, während die eigentlichen Analysen und Visualisierungen dann häufig nur noch ca. 20 Prozent der tatsächlichen Arbeitszeit für sich beanspruchen.
Pandas liefert somit viele praktische Funktionen zur Daten- und Zeitreihenanalyse und ist daher ein Standardwerkzeug in Data Science, Statistik, Finance und Machine Learning.
Auf den Doku-Seiten der Pakete oder anderen Programmiererseiten finden sich häufig kompakte Übersichten, der wichtigsten Befehle, was das Arbeiten mit dem entsprechen Pakten erleichtert: Pandas-Cheatsheet.
4.1. Pandas installieren#
Zunächst muss die Pandas-Bibliothek installiert werden. Conda erledigt dies mit dem Konsolenbefehl:
conda install -c conda-forge pandas
Alternativ kann das Paket auch mittels Pip installiert werden
pip install pandas
4.2. Numpy-Array vs. Pandas DataFrame#
Das folgende einfache Beispiel zeigt die Vorteile eines Pandas-DataFrames gegenüber einem Numpy-Array - wir betrachten einen einfachen Datensatz:
Obstsorte |
Menge |
Preis (in €) |
|---|---|---|
Apfel |
10 |
0.5 |
Banane |
5 |
0.8 |
Apfel |
7 |
0.55 |
Kirsche |
20 |
0.2 |
Die erste Spalte enthält Strings, die zweite Integer und die dritte Spalte Floats, daher sind Numpy-Arrays nur sehr umständlich zu handeln..
Pakete einbinden: das Matplotlib-Paket werden wir im folgenden Abschnitt Erstellung von Grafiken mittels Matplotlib, Seaborn und Plotly genauer betrachten und soll hier nur zur Erstellung einfacher Graphiken, die Pandas bereitstellt, aufzeigen.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
4.2.1. Umsetzung als zweidimensionales NumPy-Array#
# Daten als NumPy-Array, wegen verschiedener Typen wird dtype als object gesetzt
data = np.array([
["Apfel", 10, 0.5],
["Banane", 5, 0.8],
["Apfel", 7, 0.55],
["Kirsche", 20, 0.2]
], dtype=object)
data
array([['Apfel', 10, 0.5],
['Banane', 5, 0.8],
['Apfel', 7, 0.55],
['Kirsche', 20, 0.2]], dtype=object)
print("Datentypene 1. Zeile: %s %s %s" % (type(data[0,0]), type(data[0,1]), type(data[0,2])))
Datentypene 1. Zeile: <class 'str'> <class 'int'> <class 'float'>
Daher müssen beim Rechnen mit data immer jeweils die Typen konvertiert werden
# Umsatzspalte berechnen: Menge * Preis
umsatz = data[:,1].astype(float) * data[:,2].astype(float)
umsatz
array([5. , 4. , 3.85, 4. ])
Die Berechnung des Umsatzes für jede einzelne Produktart ist entsprechend kompliziert
# Gesamtumsatz pro Produkt (manuell gruppieren)
produkte = np.unique(data[:,0])
print("Produkte: %s" % produkte)
for p in produkte:
mask = data[:,0] == p
print(p, umsatz[mask].sum())
Produkte: ['Apfel' 'Banane' 'Kirsche']
Apfel 8.850000000000001
Banane 4.0
Kirsche 4.0
Vergleiche: Zugriff 1. Spalte (Index 0; : für gesamte Zeile)
data[:,0]
array(['Apfel', 'Banane', 'Apfel', 'Kirsche'], dtype=object)
data[:,2] #Spalte 2 (=3. Spalte)
array([0.5, 0.8, 0.55, 0.2], dtype=object)
# Durchschnittspreis
avg_preis = data[:,2].astype(float).mean()
print("Durchschnittspreis:", avg_preis)
Durchschnittspreis: 0.5125000000000001
Deutlich einfacher ist das Handling in Pandas:
4.2.2. Umsetzung in Pandas als DataFrame#
# Daten als DataFrame
df = pd.DataFrame({
"Produkt": ["Apfel", "Banane", "Apfel", "Kirsche"],
"Menge": [10, 5, 7, 20],
"Preis": [0.5, 0.8, 0.55, 0.2]
})
df
| Produkt | Menge | Preis | |
|---|---|---|---|
| 0 | Apfel | 10 | 0.50 |
| 1 | Banane | 5 | 0.80 |
| 2 | Apfel | 7 | 0.55 |
| 3 | Kirsche | 20 | 0.20 |
Hinweis: die Pandas Funktion DataFrame() bekommt im obigen Beispiel in Zeile 2 ein sogenanntes Dictionary (von Listen) übergeben, welches in geschweiften Klammern {} in Python gesetzt wird und entspricht einer Implementierung Spalte für Spalte, wobei jede Spalte für eine Variable steht. Alternativ kann der DataFrame auch zeilenweise aufgebaut werden, dann bekommt die Funktion DataFrame() eine Liste von Dictionaries (eins je Zeile) übergeben. Mit der Funktion DataFrame.append() können dann weitere Zeilen hinzugefügt werden.
Auf die einzelnen Spalten des DataFrames können wir auf folgende zwei verschiedene Arten zugreifen
df["Produkt"]
0 Apfel
1 Banane
2 Apfel
3 Kirsche
Name: Produkt, dtype: object
#falls nur 1 Variable (=1 Spalte): funktioniert der Zugriff auch mittels .
df.Preis
0 0.50
1 0.80
2 0.55
3 0.20
Name: Preis, dtype: float64
#Zugriff auf mehrere Spalten einfach mittels Liste der entsprechenden Variablen
df[["Preis","Menge"]]
| Preis | Menge | |
|---|---|---|
| 0 | 0.50 | 10 |
| 1 | 0.80 | 5 |
| 2 | 0.55 | 7 |
| 3 | 0.20 | 20 |
Neue Variablen (Spalten) können wie folgt hinzugefügt werden:
df["Umsatz"]=df["Menge"] * df["Preis"]
print(df)
Produkt Menge Preis Umsatz
0 Apfel 10 0.50 5.00
1 Banane 5 0.80 4.00
2 Apfel 7 0.55 3.85
3 Kirsche 20 0.20 4.00
#fuegen hier noch weitere Spalte Umsatz2 mit selben Werten hinzu, um Alternative aufzuzeigen
df = df.assign(Umsatz2=df["Menge"] * df["Preis"])
print(df)
Produkt Menge Preis Umsatz Umsatz2
0 Apfel 10 0.50 5.00 5.00
1 Banane 5 0.80 4.00 4.00
2 Apfel 7 0.55 3.85 3.85
3 Kirsche 20 0.20 4.00 4.00
Die Pandas-Funktionen groupby() sowie pivot_table() liefern eine sehr bequeme Möglichkeit, den Datensatz in Untergruppen zu unterteilen und dann für eine oder mehrere Variablen Berechnungen durchzuführen. Den Gesamtumstz je Produkt erhält man beispielsweise, indem wir den DataFrame nach den einzelnen Produkten gruppieren und anschließend die Umsätze summieren:
# Gesamtumsatz und verkaufte Menge je Produkt
df.groupby("Produkt")["Umsatz"].sum()
Produkt
Apfel 8.85
Banane 4.00
Kirsche 4.00
Name: Umsatz, dtype: float64
df.pivot_table("Umsatz",index="Produkt")
| Umsatz | |
|---|---|
| Produkt | |
| Apfel | 4.425 |
| Banane | 4.000 |
| Kirsche | 4.000 |
#mehrere Spalten einfach als Liste
df.groupby("Produkt")[["Umsatz","Menge","Umsatz2"]].sum()
| Umsatz | Menge | Umsatz2 | |
|---|---|---|---|
| Produkt | |||
| Apfel | 8.85 | 17 | 8.85 |
| Banane | 4.00 | 5 | 4.00 |
| Kirsche | 4.00 | 20 | 4.00 |
#oder falls sinnvoll für alle Spalten
df.groupby("Produkt").sum()
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 17 | 1.05 | 8.85 | 8.85 |
| Banane | 5 | 0.80 | 4.00 | 4.00 |
| Kirsche | 20 | 0.20 | 4.00 | 4.00 |
Ebenso können wir auf einzelne Spalten (Variablen) zahlreiche statistische Funktionen anwenden
# Durchschnittspreis
print("Durchschnittspreis:", df["Preis"].mean())
Durchschnittspreis: 0.5125000000000001
df.groupby("Produkt").mean()
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 8.5 | 0.525 | 4.425 | 4.425 |
| Banane | 5.0 | 0.800 | 4.000 | 4.000 |
| Kirsche | 20.0 | 0.200 | 4.000 | 4.000 |
mittels groupby können wir jetzt beispielsweise einfach die Anzahl für jede Obstsorte ermitteln:
Auf die Spalte bzw. Variable Menge kann ebenso mittels der zweiten Alternative zugegriffen werden:
df.groupby('Produkt').Menge.sum()
Produkt
Apfel 17
Banane 5
Kirsche 20
Name: Menge, dtype: int64
Die Befehle .loc (label-based) und .iloc (integer position-based) sind zwei sehr wichtige Instrumente in der Datenanalyse, welche wir nachfolgend ausführlicher behandeln möchten. Weitere Informationen finden Sie hier.
df_neu = pd.DataFrame({
"Produkt": ["Apfel", "Banane", "Apfel", "Kirsche"],
"Menge": [10, 5, 7, 20],
"Preis": [0.5, 0.8, 0.55, 0.2]
})
df_neu=df_neu.set_index("Produkt")
df_neu.loc["Banane"]
# Alternativ
df_neu.iloc[1]
Menge 5.0
Preis 0.8
Name: Banane, dtype: float64
Wenn wir auf mehrere Objekte zugreifen wollen, dann klappt dass wie folgt:
df_neu.loc[["Banane", "Kirsche"]]
#Alternativ
df_neu.iloc[[1,3]]
| Menge | Preis | |
|---|---|---|
| Produkt | ||
| Banane | 5 | 0.8 |
| Kirsche | 20 | 0.2 |
Wenn wir Werte miteinander vergleichen wollen, dann ist folgender Befehl hilfreich
df_neu.loc[["Kirsche", "Banane"], "Preis"]
# Alternativ
df_neu.iloc[[1,3], 1]
Produkt
Banane 0.8
Kirsche 0.2
Name: Preis, dtype: float64
4.3. Teilstichproben durch Filterbedingungen#
Bsp: Herausfiltern aller Zeilen mit Apfel, nutzen hierzu Vergleichsoperatoren
filter1 = df['Produkt']=='Apfel'
filter1
0 True
1 False
2 True
3 False
Name: Produkt, dtype: bool
Einschränkung des DataFrames auf Filter:
df[filter1]
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 0 | Apfel | 10 | 0.50 | 5.00 | 5.00 |
| 2 | Apfel | 7 | 0.55 | 3.85 | 3.85 |
df.loc[filter1]
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 0 | Apfel | 10 | 0.50 | 5.00 | 5.00 |
| 2 | Apfel | 7 | 0.55 | 3.85 | 3.85 |
Herausfiltern Menge mindestens 10
filter2 = df['Menge'] >=10
df[filter2]
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 0 | Apfel | 10 | 0.5 | 5.0 | 5.0 |
| 3 | Kirsche | 20 | 0.2 | 4.0 | 4.0 |
Logisch verknüpfte Filterbedingungen: Sollen beispielsweise alle Einkäufe von Äpfeln, die mehr als 50 Cent gekostet haben herausgefiltert werden:
Achtung während bisher Vergleichsoperatoren für Vektoren immer automatisch elementweise angewendet wurden, z.B. beim Vergleich der Sorte auf Äpfel mittels df['Produkt']=='Apfel' ist die logische Verknüpfung mehrerer Vektoren nicht mehr eindeutig, so
filter_apfel = df['Produkt'] == 'Apfel'
filter_preis = df['Preis'] > 0.5
print(filter_apfel)
print(filter_preis)
0 True
1 False
2 True
3 False
Name: Produkt, dtype: bool
0 False
1 True
2 True
3 False
Name: Preis, dtype: bool
#logische Und-Verknuepfung funktioniert nicht fuer Vektoren / Arrays - Fehlermeldung!
filter_apfel and filter_preis
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_1410930/474117169.py in ?()
1 #logische Und-Verknuepfung funktioniert nicht fuer Vektoren / Arrays - Fehlermeldung!
----> 2 filter_apfel and filter_preis
~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/generic.py in ?(self)
1578 @final
1579 def __nonzero__(self) -> NoReturn:
-> 1580 raise ValueError(
1581 f"The truth value of a {type(self).__name__} is ambiguous. "
1582 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1583 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
Für Vektoren nutzen wir die Numpy-Funktion logical_and(), die elementweise arbeitet
filter_komplex = np.logical_and(filter_apfel, filter_preis)
print(filter_komplex)
df[filter_komplex]
0 False
1 False
2 True
3 False
dtype: bool
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 2 | Apfel | 7 | 0.55 | 3.85 | 3.85 |
Alternativ kann auch & für die elementweise Und-Verknüpfung sowie | für die logische Oder-Operation anstatt np.logical_or() verwendet werden
filter_apfel & filter_preis
0 False
1 False
2 True
3 False
dtype: bool
filter_apfel | filter_preis
0 True
1 True
2 True
3 False
dtype: bool
np.logical_or(filter_apfel,filter_preis)
0 True
1 True
2 True
3 False
dtype: bool
Das Analogon zu not für elementweise Operationen ist ~ bzw. np.logical_not()
print(not True)
False
print(~filter_apfel)
0 False
1 True
2 False
3 True
Name: Produkt, dtype: bool
print(np.logical_not(filter_apfel))
0 False
1 True
2 False
3 True
Name: Produkt, dtype: bool
Filtern mittels isin() beispielsweise für Strings
obst_spezial = ["Banane","Kirsche","Birne"]
df[df["Produkt"].isin(obst_spezial)]
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 1 | Banane | 5 | 0.8 | 4.0 | 4.0 |
| 3 | Kirsche | 20 | 0.2 | 4.0 | 4.0 |
4.4. Weitere hilfreiche Pandas-Funktionen#
Pandas stellt sehr viele hilfreiche Funktionen zur Datenmanipluation für DataFrames bereit. Für Details verweisen wir auf die Pandas-Dokumentation. So haben wir bereits groupby kennengelernt, mit dem der Datensatz nach kategoriellen Variablen (eine oder mehrere) gruppiert werden und für jede einzelne Untergruppe (beispielsweise für jede Obstsorte) weitere Funktionen angewendet werden können. Häufig ist die Kombination bzw. Hintereinanderausführung solcher Befehle besonders mächtig.
Beispielhaft erstellen wir einen neuen Dataframe mit den Gesamtumsätzen je Sorte, indem wir für die Umsätze für jede einzelne Obstsorte nochmals den Gesamtumsatz ermitteln:
df2 = df.groupby("Produkt")["Umsatz"].sum()
df2
Produkt
Apfel 8.85
Banane 4.00
Kirsche 4.00
Name: Umsatz, dtype: float64
Aufgabe: Probieren Sie weitere Funktionen, die auf den DataFrame df angewendet werden können, z. B. head(),tail(), info(), shape(), describe(), agg(), value_counts() oder sort_values() sowie df.index und df.columns und df.values
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Produkt 4 non-null object
1 Menge 4 non-null int64
2 Preis 4 non-null float64
3 Umsatz 4 non-null float64
4 Umsatz2 4 non-null float64
dtypes: float64(3), int64(1), object(1)
memory usage: 292.0+ bytes
df.describe()
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| count | 4.000000 | 4.000000 | 4.000000 | 4.000000 |
| mean | 10.500000 | 0.512500 | 4.212500 | 4.212500 |
| std | 6.658328 | 0.246221 | 0.529741 | 0.529741 |
| min | 5.000000 | 0.200000 | 3.850000 | 3.850000 |
| 25% | 6.500000 | 0.425000 | 3.962500 | 3.962500 |
| 50% | 8.500000 | 0.525000 | 4.000000 | 4.000000 |
| 75% | 12.500000 | 0.612500 | 4.250000 | 4.250000 |
| max | 20.000000 | 0.800000 | 5.000000 | 5.000000 |
Zählen für kategorielle Variablen:
df["Produkt"].value_counts()
Produkt
Apfel 2
Banane 1
Kirsche 1
Name: count, dtype: int64
Bemerkung: Der Befehl .value_counts(sort=True) sortiert die Werte. Mit dem Befehl .value_counts(normalize=True) werden die anteiligen Werte für das jeweilige Produkt berechnet.
df["Produkt"].value_counts(normalize=True)
Produkt
Apfel 0.50
Banane 0.25
Kirsche 0.25
Name: proportion, dtype: float64
4.4.1. Aggregate and Apply: (dt. Aggregieren und Anwenden )#
df.apply('sum')
Produkt ApfelBananeApfelKirsche
Menge 42
Preis 2.05
Umsatz 16.85
Umsatz2 16.85
dtype: object
df.groupby("Produkt").apply("mean")
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 8.5 | 0.525 | 4.425 | 4.425 |
| Banane | 5.0 | 0.800 | 4.000 | 4.000 |
| Kirsche | 20.0 | 0.200 | 4.000 | 4.000 |
df.agg(['min', 'max', 'sum'])
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| min | Apfel | 5 | 0.20 | 3.85 | 3.85 |
| max | Kirsche | 20 | 0.80 | 5.00 | 5.00 |
| sum | ApfelBananeApfelKirsche | 42 | 2.05 | 16.85 | 16.85 |
Achtung: Nicht jede Funktion ist für jeden Datentyp beliebig anwendbar oder sinnvoll, z.B. liefert der folgende Abruf einen Fehler, da kein Mittelwert für Strings (kategorielle Variable Produkt) berechnet werden kann und dies für nominal skalierte Merkmale natürlich auch nicht sinnvoll ist
#lange Fehleranalyse ist hier ausgeblendet
df.agg(['sum',"mean"])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[47], line 2
1 #lange Fehleranalyse ist hier ausgeblendet
----> 2 df.agg(['sum',"mean"])
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/frame.py:10176, in DataFrame.aggregate(self, func, axis, *args, **kwargs)
10173 axis = self._get_axis_number(axis)
10175 op = frame_apply(self, func=func, axis=axis, args=args, kwargs=kwargs)
> 10176 result = op.agg()
10177 result = reconstruct_and_relabel_result(result, func, **kwargs)
10178 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:928, in FrameApply.agg(self)
926 result = None
927 try:
--> 928 result = super().agg()
929 finally:
930 self.obj = obj
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:193, in Apply.agg(self)
190 return self.agg_dict_like()
191 elif is_list_like(func):
192 # we require a list, but not a 'str'
--> 193 return self.agg_list_like()
195 if callable(func):
196 f = com.get_cython_func(func)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:326, in Apply.agg_list_like(self)
318 def agg_list_like(self) -> DataFrame | Series:
319 """
320 Compute aggregation in the case of a list-like argument.
321
(...)
324 Result of aggregation.
325 """
--> 326 return self.agg_or_apply_list_like(op_name="agg")
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:744, in NDFrameApply.agg_or_apply_list_like(self, op_name)
741 if getattr(obj, "axis", 0) == 1:
742 raise NotImplementedError("axis other than 0 is not supported")
--> 744 keys, results = self.compute_list_like(op_name, obj, kwargs)
745 result = self.wrap_results_list_like(keys, results)
746 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:385, in Apply.compute_list_like(self, op_name, selected_obj, kwargs)
379 colg = obj._gotitem(col, ndim=1, subset=selected_obj.iloc[:, index])
380 args = (
381 [self.axis, *self.args]
382 if include_axis(op_name, colg)
383 else self.args
384 )
--> 385 new_res = getattr(colg, op_name)(func, *args, **kwargs)
386 results.append(new_res)
387 indices.append(index)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/series.py:4785, in Series.aggregate(self, func, axis, *args, **kwargs)
4782 func = dict(kwargs.items())
4784 op = SeriesApply(self, func, args=args, kwargs=kwargs)
-> 4785 result = op.agg()
4786 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:1425, in SeriesApply.agg(self)
1424 def agg(self):
-> 1425 result = super().agg()
1426 if result is None:
1427 obj = self.obj
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:193, in Apply.agg(self)
190 return self.agg_dict_like()
191 elif is_list_like(func):
192 # we require a list, but not a 'str'
--> 193 return self.agg_list_like()
195 if callable(func):
196 f = com.get_cython_func(func)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:326, in Apply.agg_list_like(self)
318 def agg_list_like(self) -> DataFrame | Series:
319 """
320 Compute aggregation in the case of a list-like argument.
321
(...)
324 Result of aggregation.
325 """
--> 326 return self.agg_or_apply_list_like(op_name="agg")
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:744, in NDFrameApply.agg_or_apply_list_like(self, op_name)
741 if getattr(obj, "axis", 0) == 1:
742 raise NotImplementedError("axis other than 0 is not supported")
--> 744 keys, results = self.compute_list_like(op_name, obj, kwargs)
745 result = self.wrap_results_list_like(keys, results)
746 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:369, in Apply.compute_list_like(self, op_name, selected_obj, kwargs)
363 colg = obj._gotitem(selected_obj.name, ndim=1, subset=selected_obj)
364 args = (
365 [self.axis, *self.args]
366 if include_axis(op_name, colg)
367 else self.args
368 )
--> 369 new_res = getattr(colg, op_name)(a, *args, **kwargs)
370 results.append(new_res)
372 # make sure we find a good name
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/series.py:4785, in Series.aggregate(self, func, axis, *args, **kwargs)
4782 func = dict(kwargs.items())
4784 op = SeriesApply(self, func, args=args, kwargs=kwargs)
-> 4785 result = op.agg()
4786 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:1425, in SeriesApply.agg(self)
1424 def agg(self):
-> 1425 result = super().agg()
1426 if result is None:
1427 obj = self.obj
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:187, in Apply.agg(self)
184 kwargs = self.kwargs
186 if isinstance(func, str):
--> 187 return self.apply_str()
189 if is_dict_like(func):
190 return self.agg_dict_like()
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:603, in Apply.apply_str(self)
601 else:
602 self.kwargs["axis"] = self.axis
--> 603 return self._apply_str(obj, func, *self.args, **self.kwargs)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/apply.py:693, in Apply._apply_str(self, obj, func, *args, **kwargs)
691 f = getattr(obj, func)
692 if callable(f):
--> 693 return f(*args, **kwargs)
695 # people may aggregate on a non-callable attribute
696 # but don't let them think they can pass args to it
697 assert len(args) == 0
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/series.py:6570, in Series.mean(self, axis, skipna, numeric_only, **kwargs)
6562 @doc(make_doc("mean", ndim=1))
6563 def mean(
6564 self,
(...)
6568 **kwargs,
6569 ):
-> 6570 return NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/generic.py:12485, in NDFrame.mean(self, axis, skipna, numeric_only, **kwargs)
12478 def mean(
12479 self,
12480 axis: Axis | None = 0,
(...)
12483 **kwargs,
12484 ) -> Series | float:
> 12485 return self._stat_function(
12486 "mean", nanops.nanmean, axis, skipna, numeric_only, **kwargs
12487 )
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/generic.py:12442, in NDFrame._stat_function(self, name, func, axis, skipna, numeric_only, **kwargs)
12438 nv.validate_func(name, (), kwargs)
12440 validate_bool_kwarg(skipna, "skipna", none_allowed=False)
> 12442 return self._reduce(
12443 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only
12444 )
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/series.py:6478, in Series._reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds)
6473 # GH#47500 - change to TypeError to match other methods
6474 raise TypeError(
6475 f"Series.{name} does not allow {kwd_name}={numeric_only} "
6476 "with non-numeric dtypes."
6477 )
-> 6478 return op(delegate, skipna=skipna, **kwds)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/nanops.py:147, in bottleneck_switch.__call__.<locals>.f(values, axis, skipna, **kwds)
145 result = alt(values, axis=axis, skipna=skipna, **kwds)
146 else:
--> 147 result = alt(values, axis=axis, skipna=skipna, **kwds)
149 return result
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/nanops.py:404, in _datetimelike_compat.<locals>.new_func(values, axis, skipna, mask, **kwargs)
401 if datetimelike and mask is None:
402 mask = isna(values)
--> 404 result = func(values, axis=axis, skipna=skipna, mask=mask, **kwargs)
406 if datetimelike:
407 result = _wrap_results(result, orig_values.dtype, fill_value=iNaT)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/nanops.py:720, in nanmean(values, axis, skipna, mask)
718 count = _get_counts(values.shape, mask, axis, dtype=dtype_count)
719 the_sum = values.sum(axis, dtype=dtype_sum)
--> 720 the_sum = _ensure_numeric(the_sum)
722 if axis is not None and getattr(the_sum, "ndim", False):
723 count = cast(np.ndarray, count)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/nanops.py:1701, in _ensure_numeric(x)
1698 elif not (is_float(x) or is_integer(x) or is_complex(x)):
1699 if isinstance(x, str):
1700 # GH#44008, GH#36703 avoid casting e.g. strings to numeric
-> 1701 raise TypeError(f"Could not convert string '{x}' to numeric")
1702 try:
1703 x = float(x)
TypeError: Could not convert string 'ApfelBananeApfelKirsche' to numeric
Allerdings können wir das auch den Aufruf mittels Dictionaries präzisieren, welche Funktion auf welche Variablen angewendet werden soll, so dass für die Variable hier beispielsweise
#dictionary of function list
df.agg({"Produkt":["min", "max","sum"], "Preis": ["min", "max","sum", "mean","median"], "Umsatz": ["min", "max","sum", "median","mean"]})
| Produkt | Preis | Umsatz | |
|---|---|---|---|
| min | Apfel | 0.2000 | 3.8500 |
| max | Kirsche | 0.8000 | 5.0000 |
| sum | ApfelBananeApfelKirsche | 2.0500 | 16.8500 |
| mean | NaN | 0.5125 | 4.2125 |
| median | NaN | 0.5250 | 4.0000 |
sortieren:
df.sort_values(['Preis'])
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 3 | Kirsche | 20 | 0.20 | 4.00 | 4.00 |
| 0 | Apfel | 10 | 0.50 | 5.00 | 5.00 |
| 2 | Apfel | 7 | 0.55 | 3.85 | 3.85 |
| 1 | Banane | 5 | 0.80 | 4.00 | 4.00 |
df.sort_values(["Produkt","Preis"], ascending=[False,True])
| Produkt | Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|---|
| 3 | Kirsche | 20 | 0.20 | 4.00 | 4.00 |
| 1 | Banane | 5 | 0.80 | 4.00 | 4.00 |
| 0 | Apfel | 10 | 0.50 | 5.00 | 5.00 |
| 2 | Apfel | 7 | 0.55 | 3.85 | 3.85 |
Eine zentrale Fragestellung im Datenimport ist:
Haben wir NaN-Werte (NaN=not a numer)?
Wenn ja, wie viele?
Wie gehen wir damit um? Zum ersten Teil der Frage möchten wir an dieser Stelle einige Methoden vorstellen, wie wir erkennen, dass NaN-Werte in unserem importieren Datensatz haben. Mithilfe von
.isna()können wir erkennen, ob ein “richtiger Wert” in der Zelle vorhanden ist, oder nicht.
NaN_df=pd.read_csv("./../../Data/beispiel_nan.csv")
print(NaN_df)
NaN_df.isna() # Zeigt uns, ob Werte fehlen oder nicht.
Name Alter Stadt Einkommen
0 Anna 23.0 Berlin 3200.0
1 Bernd NaN München 4500.0
2 Clara 35.0 NaN NaN
3 David 29.0 Hamburg 3900.0
4 Eva NaN Köln 4100.0
| Name | Alter | Stadt | Einkommen | |
|---|---|---|---|---|
| 0 | False | False | False | False |
| 1 | False | True | False | False |
| 2 | False | False | True | True |
| 3 | False | False | False | False |
| 4 | False | True | False | False |
Auf den ersten Blick sieht die .isna()-Methode sehr attraktiv aus, jedoch könnte dies bei größeren Datensätzen problematisch werden. Deshalb ist die Kombination von .isna()und .any() in solchen Fällen besser geeignet.
NaN_df.isna().any()
Name False
Alter True
Stadt True
Einkommen True
dtype: bool
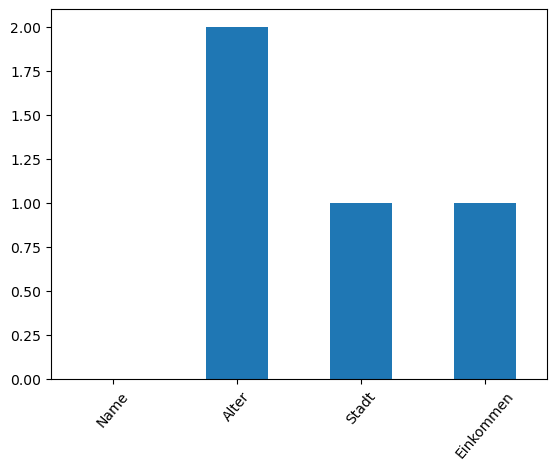
Durch diese Kombination erfahren wir, ob in einer Spalte NaN’s vorhanden sind, oder nicht. Jedoch haben wir noch keine Aussage erhalten, wie viele NaN’s vorhanden sind, was uns zur Beantwortung unserer zweiten Frage führt. Zur numerischen Lösung können wir .isna()mit .sum() kombinieren und erhalten die Nazahl der NaN’s je Spalte.
NaN_df.isna().sum()
Name 0
Alter 2
Stadt 1
Einkommen 1
dtype: int64
Wenn wir nach einer graphischen Lösung suchen, bietet der nachfolgende Code einen Ausweg
NaN_df.isna().sum().plot(kind="bar", rot=50) # mithilfe von rot, können wir unsere Beschriftung auf der x-Achse neigen.
plt.show()
Nachdem wir nun gesehen haben, wie viele Werte je Spalte fehlen, können wir uns nun der Beantwortung unserer dritten Frage widmem. Der Umgang mit NaN’s ist immer anhängig von der Situation. Am einfachsten wäre es, wenn wir vom Datenerheber einen vollständigen Datensatz (erneut) geliefert bekommen. Bedauerlicherweise wird das in der Regel kaum/nie stattfinden. Also müssen wir uns zwischen den beide Methoden entfernen und auffüllen entscheiden. Die erste Methodik ist eine sehr gewagte Methode, da uns dadurch Daten verloren gehen.
NaN_df.dropna()
| Name | Alter | Stadt | Einkommen | |
|---|---|---|---|---|
| 0 | Anna | 23.0 | Berlin | 3200.0 |
| 3 | David | 29.0 | Hamburg | 3900.0 |
In einigen Fällen kann es sinnvoll sein fehlende NaN-Werte im Datensatz mit geeigneten Werten aufzufüllen, im Folgenden Code-Beispiel illustrieren wir das einfach mit Null. Hier sollte man allerdings sehr vorsichtig vorgehen, da selbst ein Auffüllen mit Nullen in einer Spalte zwar nicht die Summe, aber statistische Maßzahlen wie das arithmetische Mittel beeinflusst. Denn das Auffüllen der Werte hat Einfluss auf die Stichprobengröße, wie das einfache Beispiel illustriert.
NaN_0 = NaN_df.fillna(0)
print(NaN_0)
Name Alter Stadt Einkommen
0 Anna 23.0 Berlin 3200.0
1 Bernd 0.0 München 4500.0
2 Clara 35.0 0 0.0
3 David 29.0 Hamburg 3900.0
4 Eva 0.0 Köln 4100.0
print("mit NaN: Summe Einkommen = %2.0f, Mittel =%2.1f, n=%i" %
(NaN_df.Einkommen.sum(), NaN_df.Einkommen.mean(), NaN_df.Einkommen.count()))
print("ohne NaN: Summe Einkommen = %2.0f, Mittel =%2.1f, n=%i" %
(NaN_0.Einkommen.sum(), NaN_0.Einkommen.mean(), NaN_0.Einkommen.count()))
mit NaN: Summe Einkommen = 15700, Mittel =3925.0, n=4
ohne NaN: Summe Einkommen = 15700, Mittel =3140.0, n=5
Für die statistische Analyse und die Erstellung von Graphiken ist das Ersetzen von NaN-Werten also nicht notwendig, da typischerweise NaN-Werte hier automatisch ignoriert werden.
print(NaN_df.info())
print(NaN_0.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 5 non-null object
1 Alter 3 non-null float64
2 Stadt 4 non-null object
3 Einkommen 4 non-null float64
dtypes: float64(2), object(2)
memory usage: 292.0+ bytes
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 5 non-null object
1 Alter 5 non-null float64
2 Stadt 5 non-null object
3 Einkommen 5 non-null float64
dtypes: float64(2), object(2)
memory usage: 292.0+ bytes
None
Achtung: Sollten Sie die Werte mit z.B. NaN_df.fillna(“Kein Wert geliefert”) auffüllen, sind später Berechnungen nicht mehr möglich, da ja verschiedene Datentypen in der Spalte vorhanden sind. So wäre zum Beispiel die Berechnung des Durchschnittsalters problematisch.
4.5. Index vs Spalten#
print("Spaltennamen = Variablen: %s \n" % df.columns)
print("Index für Zugriff auf Datenzeilen: %s" % df.index)
Spaltennamen = Variablen: Index(['Produkt', 'Menge', 'Preis', 'Umsatz', 'Umsatz2'], dtype='object')
Index für Zugriff auf Datenzeilen: RangeIndex(start=0, stop=4, step=1)
Der Index entspricht entweder der Zeilennummer – analog zu NumPy-Arrays beginnend mit 0 (d.h. 0 für die erste Zeile im Datensatz, 1 für die zweite Zeile usw) oder dem Zeilennamen bzw. Label. Beispielsweise haben Finanzdatensätze üblicherweise das Datum als Index gesetzt.
#values liefert immer array zurueck: hier wird deutlich, dass Pandas auf NumPy aufsetzt
df.values
array([['Apfel', 10, 0.5, 5.0, 5.0],
['Banane', 5, 0.8, 4.0, 4.0],
['Apfel', 7, 0.55, 3.8500000000000005, 3.8500000000000005],
['Kirsche', 20, 0.2, 4.0, 4.0]], dtype=object)
print(df)
Produkt Menge Preis Umsatz Umsatz2
0 Apfel 10 0.50 5.00 5.00
1 Banane 5 0.80 4.00 4.00
2 Apfel 7 0.55 3.85 3.85
3 Kirsche 20 0.20 4.00 4.00
df_index = df.set_index("Produkt")
print(df_index)
Menge Preis Umsatz Umsatz2
Produkt
Apfel 10 0.50 5.00 5.00
Banane 5 0.80 4.00 4.00
Apfel 7 0.55 3.85 3.85
Kirsche 20 0.20 4.00 4.00
df_index.index
Index(['Apfel', 'Banane', 'Apfel', 'Kirsche'], dtype='object', name='Produkt')
df_index.loc['Apfel']
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 10 | 0.50 | 5.00 | 5.00 |
| Apfel | 7 | 0.55 | 3.85 | 3.85 |
#ersten 2 Zeilen
df_index[:2]
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 10 | 0.5 | 5.0 | 5.0 |
| Banane | 5 | 0.8 | 4.0 | 4.0 |
#dafür funktioniert jetzt der normale Integer-Index nicht mehr und verursacht eine Fehlermeldung
df_index.loc[0:2]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[66], line 2
1 #dafür funktioniert jetzt der normale Integer-Index nicht mehr und verursacht eine Fehlermeldung
----> 2 df_index.loc[0:2]
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexing.py:1192, in _LocationIndexer.__getitem__(self, key)
1190 maybe_callable = com.apply_if_callable(key, self.obj)
1191 maybe_callable = self._check_deprecated_callable_usage(key, maybe_callable)
-> 1192 return self._getitem_axis(maybe_callable, axis=axis)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexing.py:1412, in _LocIndexer._getitem_axis(self, key, axis)
1410 if isinstance(key, slice):
1411 self._validate_key(key, axis)
-> 1412 return self._get_slice_axis(key, axis=axis)
1413 elif com.is_bool_indexer(key):
1414 return self._getbool_axis(key, axis=axis)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexing.py:1444, in _LocIndexer._get_slice_axis(self, slice_obj, axis)
1441 return obj.copy(deep=False)
1443 labels = obj._get_axis(axis)
-> 1444 indexer = labels.slice_indexer(slice_obj.start, slice_obj.stop, slice_obj.step)
1446 if isinstance(indexer, slice):
1447 return self.obj._slice(indexer, axis=axis)
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexes/base.py:6708, in Index.slice_indexer(self, start, end, step)
6664 def slice_indexer(
6665 self,
6666 start: Hashable | None = None,
6667 end: Hashable | None = None,
6668 step: int | None = None,
6669 ) -> slice:
6670 """
6671 Compute the slice indexer for input labels and step.
6672
(...)
6706 slice(1, 3, None)
6707 """
-> 6708 start_slice, end_slice = self.slice_locs(start, end, step=step)
6710 # return a slice
6711 if not is_scalar(start_slice):
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexes/base.py:6934, in Index.slice_locs(self, start, end, step)
6932 start_slice = None
6933 if start is not None:
-> 6934 start_slice = self.get_slice_bound(start, "left")
6935 if start_slice is None:
6936 start_slice = 0
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexes/base.py:6849, in Index.get_slice_bound(self, label, side)
6845 original_label = label
6847 # For datetime indices label may be a string that has to be converted
6848 # to datetime boundary according to its resolution.
-> 6849 label = self._maybe_cast_slice_bound(label, side)
6851 # we need to look up the label
6852 try:
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexes/base.py:6782, in Index._maybe_cast_slice_bound(self, label, side)
6780 # reject them, if index does not contain label
6781 if (is_float(label) or is_integer(label)) and label not in self:
-> 6782 self._raise_invalid_indexer("slice", label)
6784 return label
File ~/miniconda3/envs/finance/lib/python3.11/site-packages/pandas/core/indexes/base.py:4308, in Index._raise_invalid_indexer(self, form, key, reraise)
4306 if reraise is not lib.no_default:
4307 raise TypeError(msg) from reraise
-> 4308 raise TypeError(msg)
TypeError: cannot do slice indexing on Index with these indexers [0] of type int
#nutzen dafür iloc() Operator
df_index.iloc[0:2]
| Menge | Preis | Umsatz | Umsatz2 | |
|---|---|---|---|---|
| Produkt | ||||
| Apfel | 10 | 0.5 | 5.0 | 5.0 |
| Banane | 5 | 0.8 | 4.0 | 4.0 |
Anmerkung: Den Index abweichend von 0,1,2, .. zu setzen hat Vor- und Nachteile. Üblicherweise wird bei Finanzdaten das Handelsdatum als Index gesetzt, das werden wir aber in Kursdaten: Import und Visualisierung näher betrachten. Möchte man eine gewöhnliche Spalte als Index verwenden, setzt man diese mittels set_index() und möchte man einen Index wieder in eine normale Spalte umwandeln nutzt man die Funktion reset_index(). Zum Sortieren ist zudem die Funktion sort_index() nützlich
4.6. Einfache Pandas Graphiken#
Da Pandas auf dem mächtigen Graphik-Paket MatPlotLib aufsetzt, können auch sehr einfach Graphiken erzeugt werden:
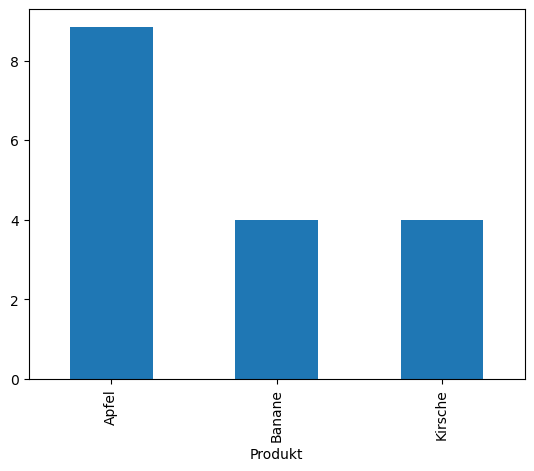
df2.plot(kind="bar")
<Axes: xlabel='Produkt'>
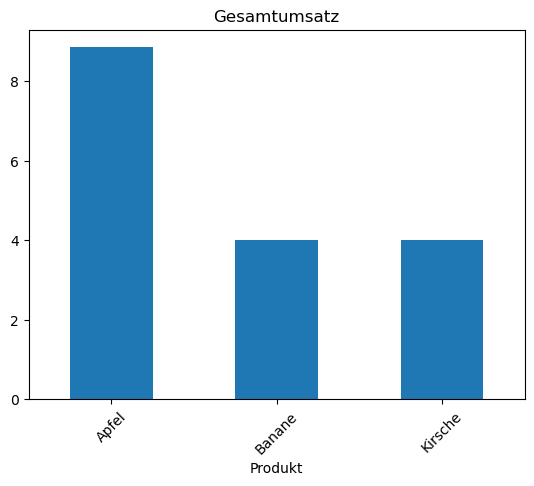
df2.plot(kind="bar",title="Gesamtumsatz", rot = 45)
<Axes: title={'center': 'Gesamtumsatz'}, xlabel='Produkt'>
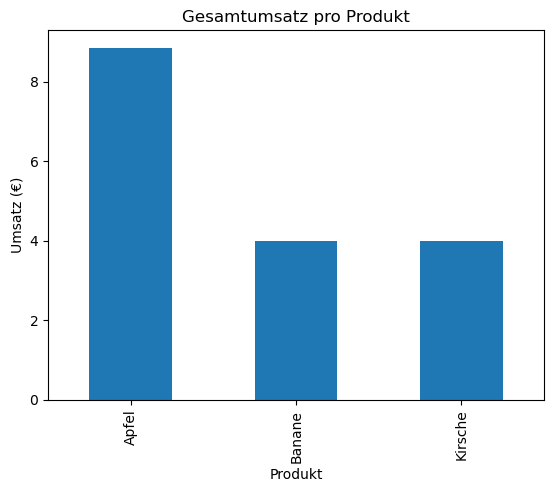
Im nächsten Abschnitt Erstellung von Grafiken mittels Matplotlib, Seaborn und Plotly sehen wir, wie wir diese Graphiken noch individueller anpassen können, z.B. neben Titel auch Labels hinzufügen:
df2.plot(kind="bar")
plt.title("Gesamtumsatz pro Produkt")
plt.ylabel("Umsatz (€)")
plt.show()
Einkommen=pd.read_csv("./../../Data/Daten_Diagramme.csv", sep=";") # sep=";" ist manchmal notwendig, wenn die Daten aus der CSV schlecht lesbar importiert werden.
# To-Do: An Ordnerstruktur anpassen
print(Einkommen.head())
Einkommen.rename(columns={"Alter<br>in Jahren" : "Alter in Jahren"}, inplace=True) #Spalte Alter umbenannt --> inplace=True => die Operation verändert das Objekt direkt (also „in place“) und gibt kein neues DataFrame zurück.
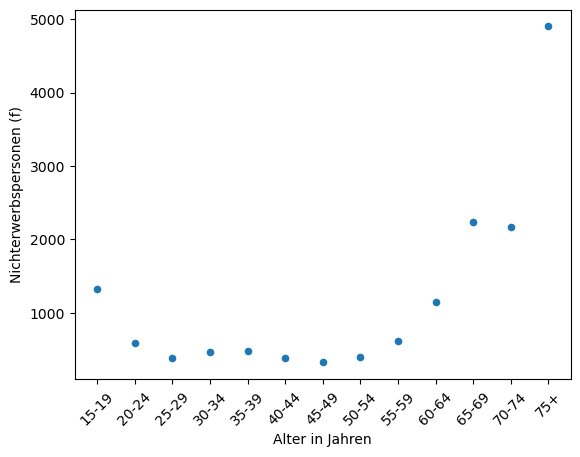
Einkommen.plot(x="Alter in Jahren", y="Nichterwerbspersonen (f)", kind="scatter", rot=45)
plt.figure(figsize=(12,5)) #Breite = 12 Zoll, Höhe = 5 Zoll
plt.show()
Alter<br>in Jahren Nichterwerbspersonen (m) Erwerbspersonen (m) \
0 15-19 1369 699
1 20-24 511 1740
2 25-29 263 2276
3 30-34 198 2584
4 35-39 180 2675
Nichterwerbspersonen (f) Erwerbspersonen (f)
0 1326 557
1 585 1528
2 387 1938
3 470 2153
4 481 2276
<Figure size 1200x500 with 0 Axes>
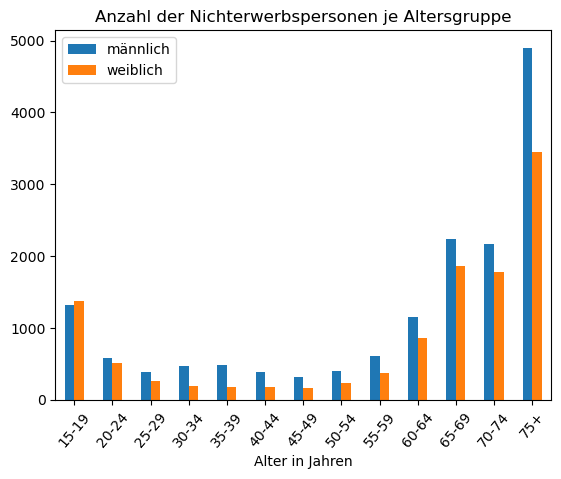
Wir können auch ein Balkendiagramm erstellen und für Vergleiche nebeneinander legen.
Einkommen.plot(
x="Alter in Jahren",
y=["Nichterwerbspersonen (f)", "Nichterwerbspersonen (m)"], # Beide Spalten in y Definieren
kind="bar",
rot=50,
title="Anzahl der Nichterwerbspersonen je Altersgruppe"
)
plt.legend(["männlich", "weiblich"])
plt.show()
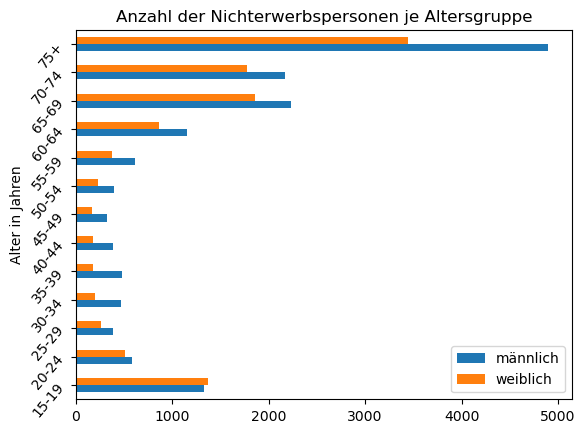
Einkommen.plot(
x="Alter in Jahren",
y=["Nichterwerbspersonen (f)", "Nichterwerbspersonen (m)"],
kind="barh", # horizntales Balkendiagramm
rot=50,
title="Anzahl der Nichterwerbspersonen je Altersgruppe"
)
plt.legend(["männlich", "weiblich"])
plt.show()
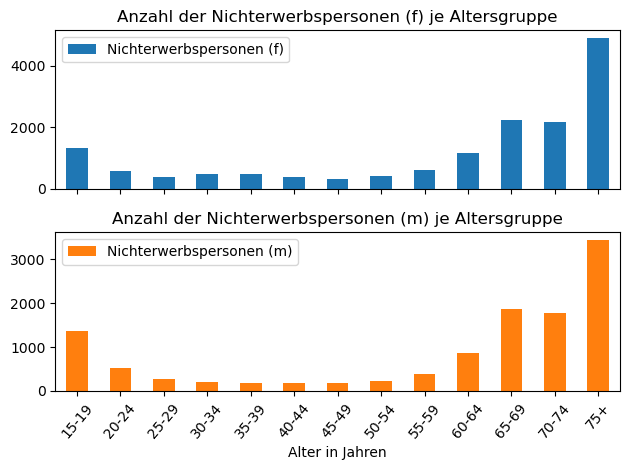
Einkommen.plot(
x="Alter in Jahren",
y=["Nichterwerbspersonen (f)", "Nichterwerbspersonen (m)"],
kind="bar",
rot=50,
subplots=True, #somit in einer Grafik zwei Diagramme dargestellt
title=[
"Anzahl der Nichterwerbspersonen (f) je Altersgruppe",
"Anzahl der Nichterwerbspersonen (m) je Altersgruppe"
]
)
plt.tight_layout() # Macht das Diagramm etwas "schöner" vom Layout her
plt.show()
Des weiteren können wir auch Histogramme übereinanderlegen.
#### Pandas
Einkommen[["Nichterwerbspersonen (f)", "Nichterwerbspersonen (m)"]].plot(
kind="hist",
bins=10, # Anzahl der Klassen
alpha=0.5, # Erhöht Transaprent
title="Verteilung der Nichterwerbspersonen (Pandas)"
)
plt.legend(["weiblich", "männlich"])
plt.xlabel("Anzahl") # Beschriftung x-Achse
plt.ylabel("Häufigkeit") # Beschriftung y-Achse
plt.show()
### Matplotlib
plt.hist(Einkommen["Nichterwerbspersonen (f)"], bins=10, alpha=0.5, label="weiblich")
plt.hist(Einkommen["Nichterwerbspersonen (m)"], bins=10, alpha=0.5, label="männlich")
plt.title("Histogramm der Nichterwerbspersonen (Matplotlib)")
plt.xlabel("Anzahl")
plt.ylabel("Häufigkeit")
plt.legend()
plt.show()
4.7. Tidy Datenformat#
Es gibt zahlreiche Möglichkeiten umfangreiche Datensätze in Tabellen-Form darzustellen. Für die Basis-Philosophie des Tidy-Formats
verweisen wir an dieser Stelle auf die Literatur und fassen hier nur kurz die grundlegende Idee zusammen.
Das Tidy Datenformat gibt eine strukturierte und standardisierte Anordnung der Daten vor, bei der jede Variable in einer eigenen Spalte steht und jede Beobachtung in einer eigenen Zeile.
Obiger DataFrame ‘Einkommen’ ist beispielsweise nicht im Tidy-Format, da das Einkommen für 4 verschiedene Gruppen (Kombinationen von Geschlecht und Erwerbstätigkeit mit jeweils 2 Ausprägungen) in 4 Spalten, statt einer abgebildet ist. Im Tidy-Format gäbe es neben der Altersgruppe eine Spalte für die Variable ‘Geschlecht’, eine Spalte für die Variable ‘Erwerbstätikeit’ und eine Spalte für die Variable ‘Einkommen’.
Dieses Prinzip bringt Übersichtlichkeit und erleichtert sämtliche Analyse- und Verarbeitungsschritte, insbesondere in Pandas.
In jeder Zelle der Tabelle darf daher nur ein Wert stehen, d. h. keine Zellen mit mehrfach codierten Informationen oder Textformatierungen.
Das folgende kleine Beispiel verletzt diese Anforderungen, da die Umsätze (1 Variable) für jedes Unternehmen ein einer extra Spalte stehen und zudem die erste Spalte sowohl das Quartal als auch das Jahr enthält.
# Nicht-tidy: Spalten sind verschiedene Unternehmen und die Zeilen verschiedene Quartale
df_umsatz = pd.DataFrame({
'Quartal': ['Q1 2024', 'Q2 2024', 'Q3 2024'],
'Apple': [28.4, 31.5, 33.2],
'Microsoft': [24.2, 25.0, 27.1],
'Google': [19.5, 20.7, 21.3]
})
print(df_umsatz)
Quartal Apple Microsoft Google
0 Q1 2024 28.4 24.2 19.5
1 Q2 2024 31.5 25.0 20.7
2 Q3 2024 33.2 27.1 21.3
Dieses sogenannte “breite” Datenforman kann mittels der Pandas Funktion melt() aber in das Tidy Format überführt werden, indem wir im ersten Schritt die Jahreszahl und das Quartal trennen und dann zusätzlich eine neue Variablen Firma einführen.
#Schritt 1: Spalte 'Quartal' in 'Quartal' und 'Jahr' aufteilen
df_umsatz[["Quartal", "Jahr"]] = df_umsatz["Quartal"].str.split(' ', expand=True)
print(df_umsatz)
Quartal Apple Microsoft Google Jahr
0 Q1 28.4 24.2 19.5 2024
1 Q2 31.5 25.0 20.7 2024
2 Q3 33.2 27.1 21.3 2024
#Schritt 2: wide to long
df_tidy = df_umsatz.melt(id_vars=['Quartal', 'Jahr'],
value_vars=['Apple', 'Microsoft', 'Google'],
var_name='Firma', value_name='Umsatz')
print(df_tidy)
Quartal Jahr Firma Umsatz
0 Q1 2024 Apple 28.4
1 Q2 2024 Apple 31.5
2 Q3 2024 Apple 33.2
3 Q1 2024 Microsoft 24.2
4 Q2 2024 Microsoft 25.0
5 Q3 2024 Microsoft 27.1
6 Q1 2024 Google 19.5
7 Q2 2024 Google 20.7
8 Q3 2024 Google 21.3
Einfache Graphiken aus Pandas…
df_tidy[df_tidy.Quartal == "Q3"].plot(x="Firma", y="Umsatz", kind = "bar", title ="Umsatz Q3 2024")
df_tidy[df_tidy.Firma == "Apple"].plot(x="Quartal", y="Umsatz", kind = "bar", title ="Umsatz Apple 2024")
<Axes: title={'center': 'Umsatz Apple 2024'}, xlabel='Quartal'>
Seaborn nutzt das tidy-Format viel effizienter. Das folgende Beispiel dient hier nur kurz der Illustration und wird nochmals in Abschnitt Graphiken mit Seaborn - to do detailierter vorgestellt.
import seaborn as sns
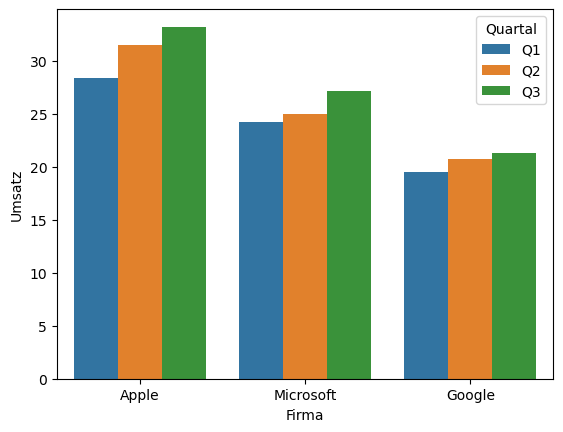
sns.barplot(data=df_tidy, x='Firma', y='Umsatz', hue='Quartal')
plt.show()
4.8. Datenexport und -import von CSV-Datensätzen und Pandas DataFrames#
Comma Separated Values (CSV) können von vielen Programmen weiterverarbeitet werden: pd.read_csv(“daten.csv”)
zum Einlesen und zum Erstellendf.to_csv(“daten.csv”)`Zum Laden von Python-Objekten ohne Konvertierung (nur für Python lesbar = Picklen):
df.to_pickle("daten.pkl")pd.read_pickle("daten.pkl")Sowohl zum Einlesen als auch Speichern einer Datei ist das aktuelle
Working directoryAusgangspunkt und kann mit der Funktiongetcwd()vom Basispaketos(operating system) abgefragt bzw. mittelschdir()angepasst werden.Liegt die einzulesende Datei nicht direkt im Working Directory, welches üblicherweise dem Quellverzeichnis des Python-Skriptes bzw. des Jupyter-Notebooks entspricht, aber auch andersweitig gesetzt werden kann, muss der Pfad zur einzulesenden Datei angegeben werden.
Hier empfielt sich die Pfadangabe mittels relativer Pfade. Soll beispielsweise die Datei
DatenDatei.csvin dem UnterordnerDaten, startet der relative Pfad im aktuellen Verzeichnis, welches mit einem.gesetzt wird:#relativer Pfad, ausgehend vom working directory df_import = pd.read_csv("./Daten/DatenDatei.csv")
Liegen die Daten hingegen in einem übergeordneten Ordner, gibt man dies im Pfad einfach mit zwei Punkten
..an. Falls also beispielsweise in Windows im OrdnerC:\Studium\Finance\Python-Kurs\es einen UnterordnerC:\Studium\Finance\Python-Kurs\Codesowie einen UnterordnerC:\Studium\Finance\Python-Kurs\Datengibt und das aktuelle Working DirectoryC:\Studium\Finance\Python-Kurs\Codeliegt, lautet der Aufruf#relativer Pfad df_import = pd.read_csv("./../Daten/DatenDatei.csv")
Der erste Punkt besagt einfach starte im Working Directory, hier also im Ordner
C:\Studium\Finance\Python-Kurs\Code. Durch die Angabe der zwei Punkte..wird dann in den übergeordneten OrdnerC:\Studium\Finance\Python-Kurs\gewechselt und dort dann die CSV-Date im OrdnerDaten\DatenDatei.csveingelesen. Der Vorteil gegenüber der Nutzung absoluter Pfade#absoluter Pfad df_import = pd.read_csv("C:/Studium/Finance/Python-Kurs/Daten/DatenDatei.csv")
liegt auf der Hand, denn dieser Aufruf funktioniert ausschließlich für die vorliegende Ordner-Struktur. Wollen Sie allerdings das Skript auf einem anderen Rechner laufen lassen, in dem obiger Ordner Python-Kurs sich beispielsweise auf
C:\users\danau\Dokumente\Finance\Python-Kursbefindet, müssten Sie den absoluten Pfad entsprechend anpassen#absoluter Pfad df_import = pd.read_csv("C:/Studium/Finance/Python-Kurs/Daten/DatenDatei.csv") #relativer Pfad df_import = pd.read_csv("./../Daten/DatenDatei.csv")
während der relative Pfad auch auf dem anderen Dateisystem funktioniert.
import os
cwd = os.getcwd()
print(cwd)
/home/mathe/lvhome20/users/personal/dana/finance-python/Script/src
4.9. Alternative Pakete zum Arbeiten mit großen Datensätzen: Exkurs in das Arbeiten mit Polars#
Polars ist eine moderne Open-Source-Bibliothek für Datenanalyse in Python und Rust, die speziell für hohe Geschwindigkeit und Speichereffizienz entwickelt wurde. Während pandas seit über einem Jahrzehnt der De-facto-Standard für tabellarische Daten in Python ist, stößt es bei sehr großen Datensätzen oder rechenintensiven Workflows oft an Performancegrenzen. Genau hier setzt Polars an: Die Bibliothek nutzt eine spaltenorientierte Speicherstruktur auf Basis von Apache Arrow und ist in Rust implementiert, wodurch sie sowohl äußerst schnell als auch ressourcenschonend arbeitet.
Ein wesentlicher Unterschied liegt in der Arbeitsweise. Pandas ist überwiegend Single-Threaded, während Polars automatisch mehrere CPU-Kerne nutzt und dadurch auf modernen Rechnern deutlich schneller ist. Außerdem unterstützt Polars eine sogenannte Lazy API: Anweisungen werden nicht sofort ausgeführt, sondern zunächst gesammelt, optimiert und dann als effiziente Query-Pipeline berechnet. Das ermöglicht Polars, Berechnungen zu beschleunigen und unnötige Operationen zu vermeiden.
Für Anwender fühlt sich Polars trotz dieser technischen Unterschiede vertraut an, da die zentrale Datenstruktur ebenfalls „DataFrame“ heißt. Viele Konzepte ähneln pandas, jedoch mit einer moderneren und oft konsistenteren Syntax. Der Nutzen für Praktiker liegt vor allem darin, dass Analysen, die mit pandas bei Millionen von Zeilen ins Stocken geraten, mit Polars problemlos und interaktiv möglich sind.
Zusammengefasst ist Polars besonders dann eine sinnvolle Alternative zu pandas, wenn es um große Datenmengen, parallele Verarbeitung und hohe Geschwindigkeit geht. Pandas hingegen bleibt weiterhin sehr stark, wenn es um breite Unterstützung im Ökosystem, Kompatibilität mit bestehenden Bibliotheken und vielfältige Tutorials geht.
Zunächst muss die Polars-Bibliothek installiert werden. Conda erledigt dies mit dem Konsolenbefehl:
conda install -c conda-forge polars
Alternativ kann das Paket auch mittels Pip installiert werden
pip install polars
Wir möchten den Einsatz von polars an dem Intraday Stock Data (1 min) – S&P 500 – 2008–21 Datensatz
mit ca. 2 Millionen Zeilen demonstrieren. Dies ist ein umfangreiches, fein aufgelöstes Zeitreihen-Datenset mit Preisdaten auf Minutenebene. Er eignet sich ausgesprochen gut zur Analyse von Marktbewegungen im Tagesverlauf oder zur Entwicklung und Validierung kurzfristiger Handels- und Vorhersagestrategien.
In Python importieren wir polars wie folgt.
import polars as pl
import polars as pl
SP500 = pl.read_csv("./../../Data/SP500_08-21.csv")
SP500.head()
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 0 | "20090522 07:30:00" | 89.45 | 89.46 | 89.37 | 89.37 | 7872 | 2102 | 89.424 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 | 1938 | 89.468 |
| 2 | "20090522 07:32:00" | 89.51 | 89.54 | 89.48 | 89.49 | 3349 | 1184 | 89.516 |
| 3 | "20090522 07:33:00" | 89.49 | 89.49 | 89.31 | 89.34 | 3495 | 1240 | 89.386 |
| 4 | "20090522 07:34:00" | 89.33 | 89.46 | 89.33 | 89.39 | 9731 | 2637 | 89.379 |
Wir sehen den Datentyp der jeweiligen Spalte in dem wir uns den Datframe mit .head() anzeigen lassen. Nachfolgend sehen wir, dass der .tail() analog zu pandas funktioniert. Sowohl beim .head() als auch bei .tail() wird uns die Anzahl der angezeigten Zeilen und Spalten wiedergegeben.
SP500.tail()
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 2070829 | "20101222 13:55:00" | 125.73 | 125.73 | 125.71 | 125.71 | 1876 | 677 | 125.714 |
| 2070830 | "20101222 13:56:00" | 125.71 | 125.74 | 125.71 | 125.74 | 4769 | 1011 | 125.724 |
| 2070831 | "20101222 13:57:00" | 125.74 | 125.74 | 125.73 | 125.74 | 2602 | 588 | 125.738 |
| 2070832 | "20101222 13:58:00" | 125.74 | 125.82 | 125.73 | 125.81 | 22953 | 2866 | 125.776 |
| 2070833 | "20101222 13:59:00" | 125.82 | 125.82 | 125.77 | 125.78 | 12895 | 2149 | 125.793 |
Wenn wir uns die genaue Anzahl der Zeilen und Spalten wiedergeben lassen wollen, verwenden wir .shape.
SP500.shape
(2070834, 9)
Mit dem Befehl .glimpse wird uns die Anzahl der gesamten Zeilen und Spalten und die Datentypen der jeweiligen Spalte wiedergegeben.
SP500.glimpse
<bound method DataFrame.glimpse of shape: (2_070_834, 9)
┌─────────┬────────────────────┬────────┬────────┬───┬────────┬────────┬──────────┬─────────┐
│ ┆ date ┆ open ┆ high ┆ … ┆ close ┆ volume ┆ barCount ┆ average │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ f64 ┆ ┆ f64 ┆ i64 ┆ i64 ┆ f64 │
╞═════════╪════════════════════╪════════╪════════╪═══╪════════╪════════╪══════════╪═════════╡
│ 0 ┆ 20090522 07:30:00 ┆ 89.45 ┆ 89.46 ┆ … ┆ 89.37 ┆ 7872 ┆ 2102 ┆ 89.424 │
│ 1 ┆ 20090522 07:31:00 ┆ 89.38 ┆ 89.53 ┆ … ┆ 89.5 ┆ 5336 ┆ 1938 ┆ 89.468 │
│ 2 ┆ 20090522 07:32:00 ┆ 89.51 ┆ 89.54 ┆ … ┆ 89.49 ┆ 3349 ┆ 1184 ┆ 89.516 │
│ 3 ┆ 20090522 07:33:00 ┆ 89.49 ┆ 89.49 ┆ … ┆ 89.34 ┆ 3495 ┆ 1240 ┆ 89.386 │
│ 4 ┆ 20090522 07:34:00 ┆ 89.33 ┆ 89.46 ┆ … ┆ 89.39 ┆ 9731 ┆ 2637 ┆ 89.379 │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 2070829 ┆ 20101222 13:55:00 ┆ 125.73 ┆ 125.73 ┆ … ┆ 125.71 ┆ 1876 ┆ 677 ┆ 125.714 │
│ 2070830 ┆ 20101222 13:56:00 ┆ 125.71 ┆ 125.74 ┆ … ┆ 125.74 ┆ 4769 ┆ 1011 ┆ 125.724 │
│ 2070831 ┆ 20101222 13:57:00 ┆ 125.74 ┆ 125.74 ┆ … ┆ 125.74 ┆ 2602 ┆ 588 ┆ 125.738 │
│ 2070832 ┆ 20101222 13:58:00 ┆ 125.74 ┆ 125.82 ┆ … ┆ 125.81 ┆ 22953 ┆ 2866 ┆ 125.776 │
│ 2070833 ┆ 20101222 13:59:00 ┆ 125.82 ┆ 125.82 ┆ … ┆ 125.78 ┆ 12895 ┆ 2149 ┆ 125.793 │
└─────────┴────────────────────┴────────┴────────┴───┴────────┴────────┴──────────┴─────────┘>
Wollen wir mal die Importzeit zwischen polars und pandas vergleichen, um zu sehen, welches Package den Datensatz schneller importiert.
import time
# Polars
start_time_polars=time.time()
SP500 = pl.read_csv("./../../Data/SP500_08-21.csv")
end_time_polars= time.time()
# Pandas
start_time_pandas=time.time()
SP500_pd=pd.read_csv("./../../Data/SP500_08-21.csv")
end_time_pandas=time.time()
print(f"Die Importzeit mit Polars beträgt {end_time_polars - start_time_polars:.2f} Sekunden und mit Pandas {end_time_pandas - start_time_pandas:.2f} Sekunden.")
Die Importzeit mit Polars beträgt 0.18 Sekunden und mit Pandas 2.14 Sekunden.
Nachfolgend stellen wir Ihnen eine Selecting-Befehle vor.
SP500[1]
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 | 1938 | 89.468 |
SP500[-1]
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 2070833 | "20101222 13:59:00" | 125.82 | 125.82 | 125.77 | 125.78 | 12895 | 2149 | 125.793 |
SP500[0:3]
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 0 | "20090522 07:30:00" | 89.45 | 89.46 | 89.37 | 89.37 | 7872 | 2102 | 89.424 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 | 1938 | 89.468 |
| 2 | "20090522 07:32:00" | 89.51 | 89.54 | 89.48 | 89.49 | 3349 | 1184 | 89.516 |
SP500["open"]
| open |
|---|
| f64 |
| 89.45 |
| 89.38 |
| 89.51 |
| 89.49 |
| 89.33 |
| … |
| 125.73 |
| 125.71 |
| 125.74 |
| 125.74 |
| 125.82 |
SP500[["open", "close"]]
| open | close |
|---|---|
| f64 | f64 |
| 89.45 | 89.37 |
| 89.38 | 89.5 |
| 89.51 | 89.49 |
| 89.49 | 89.34 |
| 89.33 | 89.39 |
| … | … |
| 125.73 | 125.71 |
| 125.71 | 125.74 |
| 125.74 | 125.74 |
| 125.74 | 125.81 |
| 125.82 | 125.78 |
SP500[:3, ["date", "open", "close"]]
| date | open | close |
|---|---|---|
| str | f64 | f64 |
| "20090522 07:30:00" | 89.45 | 89.37 |
| "20090522 07:31:00" | 89.38 | 89.5 |
| "20090522 07:32:00" | 89.51 | 89.49 |
SP500.select("date", "volume")
| date | volume |
|---|---|
| str | i64 |
| "20090522 07:30:00" | 7872 |
| "20090522 07:31:00" | 5336 |
| "20090522 07:32:00" | 3349 |
| "20090522 07:33:00" | 3495 |
| "20090522 07:34:00" | 9731 |
| … | … |
| "20101222 13:55:00" | 1876 |
| "20101222 13:56:00" | 4769 |
| "20101222 13:57:00" | 2602 |
| "20101222 13:58:00" | 22953 |
| "20101222 13:59:00" | 12895 |
SP500.sort("volume", descending=True)
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 1646096 | "20090112 14:00:00" | 87.0 | 87.05 | 86.93 | 87.0 | 331282 | 3991 | 86.942 |
| 1428792 | "20090217 14:00:00" | 79.22 | 79.32 | 79.19 | 79.23 | 271287 | 4123 | 79.194 |
| 1642556 | "20090106 14:00:00" | 93.44 | 93.5 | 93.37 | 93.48 | 194818 | 2827 | 93.441 |
| 912092 | "20090206 14:00:00" | 86.96 | 87.04 | 86.89 | 87.01 | 192291 | 3297 | 86.996 |
| 1039865 | "20090206 14:00:00" | 86.96 | 87.04 | 86.89 | 87.01 | 192291 | 3297 | 86.996 |
| … | … | … | … | … | … | … | … | … |
| 2067285 | "20200806 17:36:00" | 334.2 | 334.2 | 334.2 | 334.2 | 0 | 0 | 334.2 |
| 2067286 | "20200806 17:37:00" | 334.2 | 334.2 | 334.2 | 334.2 | 0 | 0 | 334.2 |
| 2067288 | "20200806 17:39:00" | 334.25 | 334.25 | 334.25 | 334.25 | 0 | 0 | 334.25 |
| 2067290 | "20200806 17:41:00" | 334.24 | 334.24 | 334.24 | 334.24 | 0 | 0 | 334.24 |
| 2067292 | "20200806 17:43:00" | 334.24 | 334.24 | 334.24 | 334.24 | 0 | 0 | 334.24 |
SP500.top_k(3, by="volume")
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 1646096 | "20090112 14:00:00" | 87.0 | 87.05 | 86.93 | 87.0 | 331282 | 3991 | 86.942 |
| 1428792 | "20090217 14:00:00" | 79.22 | 79.32 | 79.19 | 79.23 | 271287 | 4123 | 79.194 |
| 1642556 | "20090106 14:00:00" | 93.44 | 93.5 | 93.37 | 93.48 | 194818 | 2827 | 93.441 |
SP500.describe()
| statistic | date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|---|
| str | f64 | str | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
| "count" | 2.070834e6 | "2070834" | 2.070834e6 | 2.070834e6 | 2.070834e6 | 2.070834e6 | 2.070834e6 | 2.070834e6 | 2.070834e6 |
| "null_count" | 0.0 | "0" | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| "mean" | 1035416.5 | null | 209.097031 | 209.147645 | 209.045987 | 209.09703 | 2703.770535 | 838.816468 | 209.096867 |
| "std" | 597798.428011 | null | 84.087728 | 84.095203 | 84.079923 | 84.0877 | 3826.367469 | 974.384691 | 84.087576 |
| "min" | 0.0 | "20080122 07:30:00" | 67.12 | 67.2 | 67.1 | 67.12 | 0.0 | 0.0 | 67.152 |
| "25%" | 517708.0 | null | 133.14 | 133.17 | 133.1 | 133.14 | 659.0 | 276.0 | 133.139 |
| "50%" | 1.035417e6 | null | 202.88 | 202.93 | 202.83 | 202.88 | 1503.0 | 548.0 | 202.88 |
| "75%" | 1.553125e6 | null | 277.63 | 277.7 | 277.57 | 277.63 | 3265.0 | 1055.0 | 277.634 |
| "max" | 2.070833e6 | "20210506 13:59:00" | 420.67 | 420.72 | 420.4 | 420.67 | 331282.0 | 30245.0 | 420.535 |
Mit dem Befehl pl.col() integriert in .select() werden uns zwei bestimmte Spalten wiedergegeben.
SP500.select(
"date",
pl.col("volume")
)
| date | volume |
|---|---|
| str | i64 |
| "20090522 07:30:00" | 7872 |
| "20090522 07:31:00" | 5336 |
| "20090522 07:32:00" | 3349 |
| "20090522 07:33:00" | 3495 |
| "20090522 07:34:00" | 9731 |
| … | … |
| "20101222 13:55:00" | 1876 |
| "20101222 13:56:00" | 4769 |
| "20101222 13:57:00" | 2602 |
| "20101222 13:58:00" | 22953 |
| "20101222 13:59:00" | 12895 |
Wir können auch Modifizierungen ganz bequem durchführen. In unserem Codebeispiel kombinieren wir ein pl.col(), .round() und .alias().
SP500.select(
"date",
(pl.col("close")).round(2).alias("Schlusskurs")
)
| date | Schlusskurs |
|---|---|
| str | f64 |
| "20090522 07:30:00" | 89.37 |
| "20090522 07:31:00" | 89.5 |
| "20090522 07:32:00" | 89.49 |
| "20090522 07:33:00" | 89.34 |
| "20090522 07:34:00" | 89.39 |
| … | … |
| "20101222 13:55:00" | 125.71 |
| "20101222 13:56:00" | 125.74 |
| "20101222 13:57:00" | 125.74 |
| "20101222 13:58:00" | 125.81 |
| "20101222 13:59:00" | 125.78 |
Des weiteren ist möglich eine Spalte in unserem Dataframe zu ergänzen. Im nachfolgende Codebeispiel wollen wir sehen, ob Werte in der Spalte volume existieren. Dazu verwenden wir das Kommando pl.lit().
SP500.select(
"date",
(pl.col("volume")).round(2).alias("Handelsvolumen"),
pl.lit(True).alias("available")
)
| date | Handelsvolumen | available |
|---|---|---|
| str | i64 | bool |
| "20090522 07:30:00" | 7872 | true |
| "20090522 07:31:00" | 5336 | true |
| "20090522 07:32:00" | 3349 | true |
| "20090522 07:33:00" | 3495 | true |
| "20090522 07:34:00" | 9731 | true |
| … | … | … |
| "20101222 13:55:00" | 1876 | true |
| "20101222 13:56:00" | 4769 | true |
| "20101222 13:57:00" | 2602 | true |
| "20101222 13:58:00" | 22953 | true |
| "20101222 13:59:00" | 12895 | true |
SP500.select(
"date",
"volume",
pl.col("volume").mean().alias("average volume"),
pl.col("volume").max().alias("max volume")
)
| date | volume | average volume | max volume |
|---|---|---|---|
| str | i64 | f64 | i64 |
| "20090522 07:30:00" | 7872 | 2703.770535 | 331282 |
| "20090522 07:31:00" | 5336 | 2703.770535 | 331282 |
| "20090522 07:32:00" | 3349 | 2703.770535 | 331282 |
| "20090522 07:33:00" | 3495 | 2703.770535 | 331282 |
| "20090522 07:34:00" | 9731 | 2703.770535 | 331282 |
| … | … | … | … |
| "20101222 13:55:00" | 1876 | 2703.770535 | 331282 |
| "20101222 13:56:00" | 4769 | 2703.770535 | 331282 |
| "20101222 13:57:00" | 2602 | 2703.770535 | 331282 |
| "20101222 13:58:00" | 22953 | 2703.770535 | 331282 |
| "20101222 13:59:00" | 12895 | 2703.770535 | 331282 |
Wir wollen nun eine neue Spalte erzeugen, welche uns stets den Durchschnittskurs wiedergibt. Dazu verwenden wir .with_columns.
SP500.with_columns(
((pl.col("high")+pl.col("low"))*1/2).alias("average price")
)
| date | open | high | low | close | volume | barCount | average | average price | |
|---|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 | f64 |
| 0 | "20090522 07:30:00" | 89.45 | 89.46 | 89.37 | 89.37 | 7872 | 2102 | 89.424 | 89.415 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 | 1938 | 89.468 | 89.45 |
| 2 | "20090522 07:32:00" | 89.51 | 89.54 | 89.48 | 89.49 | 3349 | 1184 | 89.516 | 89.51 |
| 3 | "20090522 07:33:00" | 89.49 | 89.49 | 89.31 | 89.34 | 3495 | 1240 | 89.386 | 89.4 |
| 4 | "20090522 07:34:00" | 89.33 | 89.46 | 89.33 | 89.39 | 9731 | 2637 | 89.379 | 89.395 |
| … | … | … | … | … | … | … | … | … | … |
| 2070829 | "20101222 13:55:00" | 125.73 | 125.73 | 125.71 | 125.71 | 1876 | 677 | 125.714 | 125.72 |
| 2070830 | "20101222 13:56:00" | 125.71 | 125.74 | 125.71 | 125.74 | 4769 | 1011 | 125.724 | 125.725 |
| 2070831 | "20101222 13:57:00" | 125.74 | 125.74 | 125.73 | 125.74 | 2602 | 588 | 125.738 | 125.735 |
| 2070832 | "20101222 13:58:00" | 125.74 | 125.82 | 125.73 | 125.81 | 22953 | 2866 | 125.776 | 125.775 |
| 2070833 | "20101222 13:59:00" | 125.82 | 125.82 | 125.77 | 125.78 | 12895 | 2149 | 125.793 | 125.795 |
Wenn wir eine Spalte umbenennen wollen, können wir das mit .rename().
SP500.rename({
"date":"Datum"
})
| Datum | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 | i64 | f64 |
| 0 | "20090522 07:30:00" | 89.45 | 89.46 | 89.37 | 89.37 | 7872 | 2102 | 89.424 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 | 1938 | 89.468 |
| 2 | "20090522 07:32:00" | 89.51 | 89.54 | 89.48 | 89.49 | 3349 | 1184 | 89.516 |
| 3 | "20090522 07:33:00" | 89.49 | 89.49 | 89.31 | 89.34 | 3495 | 1240 | 89.386 |
| 4 | "20090522 07:34:00" | 89.33 | 89.46 | 89.33 | 89.39 | 9731 | 2637 | 89.379 |
| … | … | … | … | … | … | … | … | … |
| 2070829 | "20101222 13:55:00" | 125.73 | 125.73 | 125.71 | 125.71 | 1876 | 677 | 125.714 |
| 2070830 | "20101222 13:56:00" | 125.71 | 125.74 | 125.71 | 125.74 | 4769 | 1011 | 125.724 |
| 2070831 | "20101222 13:57:00" | 125.74 | 125.74 | 125.73 | 125.74 | 2602 | 588 | 125.738 |
| 2070832 | "20101222 13:58:00" | 125.74 | 125.82 | 125.73 | 125.81 | 22953 | 2866 | 125.776 |
| 2070833 | "20101222 13:59:00" | 125.82 | 125.82 | 125.77 | 125.78 | 12895 | 2149 | 125.793 |
Eine Spalte zu löschen funktioniert mit dem drop() Kommando.
SP500.drop("barCount", "average")
| date | open | high | low | close | volume | |
|---|---|---|---|---|---|---|
| i64 | str | f64 | f64 | f64 | f64 | i64 |
| 0 | "20090522 07:30:00" | 89.45 | 89.46 | 89.37 | 89.37 | 7872 |
| 1 | "20090522 07:31:00" | 89.38 | 89.53 | 89.37 | 89.5 | 5336 |
| 2 | "20090522 07:32:00" | 89.51 | 89.54 | 89.48 | 89.49 | 3349 |
| 3 | "20090522 07:33:00" | 89.49 | 89.49 | 89.31 | 89.34 | 3495 |
| 4 | "20090522 07:34:00" | 89.33 | 89.46 | 89.33 | 89.39 | 9731 |
| … | … | … | … | … | … | … |
| 2070829 | "20101222 13:55:00" | 125.73 | 125.73 | 125.71 | 125.71 | 1876 |
| 2070830 | "20101222 13:56:00" | 125.71 | 125.74 | 125.71 | 125.74 | 4769 |
| 2070831 | "20101222 13:57:00" | 125.74 | 125.74 | 125.73 | 125.74 | 2602 |
| 2070832 | "20101222 13:58:00" | 125.74 | 125.82 | 125.73 | 125.81 | 22953 |
| 2070833 | "20101222 13:59:00" | 125.82 | 125.82 | 125.77 | 125.78 | 12895 |
Wir können auch mithilfe von null.count() die Anzahl der fehlenden Werte ausgeben lassen.
Bemerkung: In polars werden die fehlenden Werte nicht mit NaN angegeben, sondern mit einer null.
SP500.null_count()
| date | open | high | low | close | volume | barCount | average | |
|---|---|---|---|---|---|---|---|---|
| u32 | u32 | u32 | u32 | u32 | u32 | u32 | u32 | u32 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Wir wollen an dieser Stelle den Exkurs in polars beenden. Interessierte finden unter
Polars Package weitere Ausführung.