Parallelization
Preparation¶
Current developments in computer technology are moving towards integrating more and more processors into a single system. For example, the currently most powerful supercomputer according to https://top500.org, Frontier (Oak Ridge, USA), has more than 8 million computing cores. We want to take advantage of such hardware when developing efficient algorithms.
So far, our algorithms have been more or less sequential. This means that our program is executed line by line on a single processor core. The counterpart to sequential programming is parallel programming.
The basic idea is to divide a problem into several subproblems that can be processed as independently as possible and simultaneously by multiple computing units. The partial results of these processes must then be combined into a final result. A central aspect of parallel programs is therefore the communication between processes.
First, we install the required module in our Conda environment:
conda install -c conda-forge mpi4pyMPI stands for Message Passing Interface. It is a standardized interface that provides functions for communication between parallel processes.
Let us first test whether the installation was successful. To do this, we write a simple program
print("Hello world")Output
Hello world
and save it in a file named hello_world.py.
To run the program four times in parallel, we enter the following command in the terminal:
mpirun -np 4 python hello_world.pyWe obtain the following output:
Hello world
Hello world
Hello world
Hello worldThis is, of course, not yet a true parallel program. Our script is simply started four times simultaneously.
The idea is now to make an algorithm more efficient by dividing the underlying problem into subproblems that are as independent as possible and can be computed in parallel. Ideally, these subproblems require only minimal communication with each other.
We illustrate the basic concepts with a very simple example:
This task can be parallelized almost perfectly. For example, for :
Process 1 computes the sum from 1 to 25,
Process 2 computes the sum from 26 to 50,
Process 3 computes the sum from 51 to 75,
Process 4 computes the sum from 76 to 100.
The intermediate results are then sent to a main process, which computes the final result from them.
Formally, for processes, we obtain the following representation:
For simplicity, we first assume that is divisible by .
Our program should therefore be structured such that each process computes the inner sum, while the main process subsequently computes the outer sum.
For communication between the individual processes, a so-called communicator object is used. In the following example, we store the so-called world communicator in the variable comm. With this object, we can determine both the rank of a process and the total number of processes:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
print(f"Hello! I am process {rank+1} of {size}.")When executing the program with
mpirun -np 4 python first_mpi_prog.pywe obtain the following output:
Hello! I am process 2 of 4.
Hello! I am process 1 of 4.
Hello! I am process 4 of 4.
Hello! I am process 3 of 4.It is noticeable that the order of the outputs is not fixed. The process that reaches the print statement first will also write to the console first.
In many programs, it is therefore necessary to distinguish whether the current code is being executed by the main process or by a worker process. This can be implemented, for example, using the following case distinction:
if rank == 0:
[instructions for the main process]
else:
[instructions for worker processes]The main process is typically responsible for:
distributing input data to the worker processes,
collecting intermediate results, and
computing or further processing the final result.
Simple communication with Send and Recv¶
The simplest form of data exchange between two processes is so-called point-to-point communication using the methods comm.recv(...) and comm.send(...) of the communicator object. From the code documentation, we see that these functions are called with the following parameters:
comm.send(obj, dest, tag=0)
obj = comm.recv(buf=None, source=ANY_SOURCE, tag=ANY_TAG, status=None)The sending process calls the send method. The data to be sent is passed as the first argument obj. The second argument dest specifies the rank of the receiving process.
At the same time, the receiving process calls the recv method, which returns the received object.
It is often also useful to set the tag parameter. This allows messages to be labeled with a specific identifier so that the receiver can selectively filter for certain messages. For our purposes, we do not need the remaining parameters for now.
It should also be noted that send and recv are blocking operations. This means that the program waits at this point and only proceeds to the next line once the corresponding counterpart has sent or received the data.
Both functions also exist in a non-blocking variant called isend and irecv. However, we will not go into these in more detail here.
Let us test these methods using our example. First, each process determines its rank and sets the start and end indices for the summation accordingly, as in the inner sum in (2). Then each process solves its subproblem:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
N = 1000
# Set parameters for each process
start_idx = rank*N//size+1
end_idx = (rank+1)*N//size
# Short info
print("I am process", rank, "and I will sum up the numbers", start_idx, "to", end_idx)
# Solve subproblem
val = sum(range(start_idx, end_idx+1))
Now the main process must collect all intermediate results and sum them up. The main process calls recv times with different sources (source=1, 2, ..., size-1). Each worker process sends its result to the main process using the send method (dest=0):
if rank == 0:
# main process
for i in range(1, size):
tmp = comm.recv(tag=1, source=i)
val = val + tmp
else:
# worker processes
comm.send(val, 0, tag=1)
if rank == 0:
print("The sum of 1 to", N, "is", val)Output:
I am process 3 and I will sum up the numbers 751 to 1000
I am process 1 and I will sum up the numbers 251 to 500
I am process 2 and I will sum up the numbers 501 to 750
I am process 0 and I will sum up the numbers 1 to 250
The sum of 1 to 1000 is 500500The tag parameter is optional in both the send and recv functions. However, in programs with multiple communication phases, it is useful to ensure that the correct send and recv calls match each other.
Further processing of the data—in this case, printing the result to the console—is performed only in the main process.
Note that the final result is initially available only in the main process. If the total result is also needed by the worker processes, the main process can distribute it to all other processes, for example using send and recv.
Later, we will learn about the bcast function, which makes it much easier to distribute such data to all processes at once.
Task distribution with bcast and scatter¶
We now want to get to know two additional functions:
obj = comm.bcast(obj, root=0)
obj = comm.scatter(sendobj, root=0)The broadcast method bcast sends the same data to all processes.
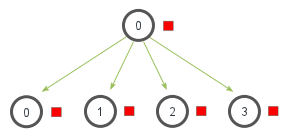
Broadcast
We could, for example, adapt our program so that the computed final result, which is initially only available in the main process, is sent to all other processes. This may be necessary to start the next subtask in our algorithm.
In most cases, the main process has rank 0. Therefore, the default value for the parameter root is usually sufficient. The received data is then available in the return value obj.
We extend the previous example with the following lines:
val = comm.bcast(val)
print("I am process", rank, "and I also know the answer:", val)Output:
I am process 0 and I also know the answer: 500500
I am process 1 and I also know the answer: 500500
I am process 2 and I also know the answer: 500500
I am process 3 and I also know the answer: 500500Note that the variable val is already defined in each process and, in the worker processes, initially still contains the result of the respective subtask. That the value in val is sent from the main process is specified by the function parameter root=0.
If we change the line, for example, to
val = comm.bcast(val, root=1)then all processes would instead receive the intermediate result from the process with rank 1.
Let us now take a look at the scatter method.
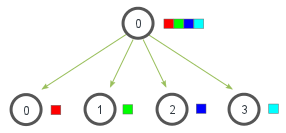
Scatter
This method can be used to distribute data generated by the main process to all processes.
Let us briefly discuss the input and output parameters of scatter. The first parameter sendobj must be a list in the main process, where the -th element is the object that should be sent to the process with rank .
In the worker processes, sendobj must also be defined; we simply set
sendobj = NoneThe second parameter root, with a default value of 0, is only relevant if the data to be sent comes from a process other than the main process. In this case, root must contain the rank of that process.
We test this with the following example:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank==0:
sendobj = [i for i in range(size)]
print("sendobj:", sendobj)
else:
sendobj = None
obj = comm.scatter(sendobj)
print("I am process", rank, "and i received the data", obj)Output:
sendobj: [0, 1, 2, 3]
I am process 0 and i received the data 0
I am process 1 and i received the data 1
I am process 2 and i received the data 2
I am process 3 and i received the data 3We now want to use the scatter function in our summation example to make the lines
start_idx = rank*N//size + 1
end_idx = (rank+1)*N//sizea bit more general.
Although each process already knows the relevant parameters start_idx and end_idx at the start of the program, there are many situations in which the parameters required by the worker processes are determined only at runtime.
For example, these parameters could
depend on user input, or
depend on the result of a previous step in our algorithm.
We therefore replace the two lines with the following code:
if rank == 0:
N = 10000
# Prepare parameters for all processes
start_indices = [p*N//size + 1 for p in range(size)]
end_indices = [(p+1)*N//size for p in range(size)]
# Create a list of tuples of the form (start_idx, end_idx)
sendobj = [(start_indices[p], end_indices[p]) for p in range(size)]
else:
sendobj = None
data = comm.scatter(sendobj, root=0)
# Extract parameters from received object
start_idx = data[0]
end_idx = data[1]
# Short info
print("I am process", rank, "and I will sum up the numbers", start_idx, "to", end_idx)The main process first creates a list with the parameters start_idx and end_idx for all processes. The sendobj that is distributed to the processes is a list whose elements are tuples of the form (start_idx, end_idx).
The worker processes then extract both parameters from their assigned tuple and can begin solving their subtask.
Combining processes with reduce and gather¶
The way we send the intermediate results back to the main process for further processing is somewhat suboptimal in our example:
if rank == 0:
# main process
for i in range(1, size):
tmp = comm.recv(tag=1, source=i)
val = val + tmp
else:
# worker processes
comm.send(val, 0, tag=1)The results are sent to the main process one after another. For such situations, the methods reduce and gather are usually better suited.
From the code documentation, we obtain the following calls:
val = reduce(sendobj, op=MPI.SUM, root=0)
List = gather(sendobj, root=0)In both cases, the first parameter sendobj is the object that contains the intermediate result of each process.
The optional parameter root specifies which process should receive the final result. By default, this is the process with rank 0.
The reduce method additionally requires the parameter op. This is an operation that is applied to the intermediate results to compute the final result.
The most important operations are:
| Operation | Description |
|---|---|
MPI.SUM | Sums up all values |
MPI.PROD | Multiplies all values |
MPI.MAX | Determines the maximum of all values |
MPI.MAXLOC | Determines the maximum and the rank of the corresponding process |
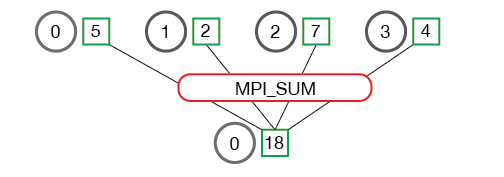
Reduce
Let us try this method for our example. We replace the code above with:
val = comm.reduce(val, op=MPI.SUM, root=0)This sums up the values of the variable val from all processes. The result is stored in the process with rank 0.
The gather method works somewhat differently. In principle, it is the counterpart to the scatter method.
While scatter distributes a list of data across multiple processes, gather collects the data from all processes and stores it in a list, which can then be further processed by the root process.
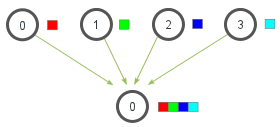
Gather
Applied to our example, this looks as follows:
all_vals = comm.gather(val)
if rank == 0:
print(f"Gather gives me the following list: {all_vals}")
# Sum this list
val = sum(all_vals)
print("The sum of 1 to", N, "is", val)Output:
Gather gives me the following list: [3126250, 9376250, 15626250, 21876250]
The sum of 1 to 10000 is 50005000.The complete code for solving our example is:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
N = 1000
# Compute start and end indices
start_indices = [int(p*N/size + 1) for p in range(size)]
end_indices = [int((p+1)*N/size) for p in range(size)]
# Collect into a list
sendobj = [(start_indices[p], end_indices[p]) for p in range(size)]
else:
sendobj = None
# Send indices to worker processes
data = comm.scatter(sendobj, root=0)
# Unpack indices
start_idx = data[0]
end_idx = data[1]
print(f"Hello! I am process {rank+1} of {size}. I sum up {start_idx} to {end_idx}")
# Solve subproblems
val = sum(range(start_idx, end_idx + 1))
# Send data to the main process
# Option 1: via send/recv
# if rank == 0:
# for i in range(1, size):
# tmp = comm.recv(source=i, tag=7)
# val = val + tmp
# else:
# comm.send(val, dest=0, tag=7)
# Option 2: via gather
# all_vals = comm.gather(val, root=0)
# if rank == 0:
# print(f"Gather gives me the following list: {all_vals}")
# val = sum(all_vals)
# Option 3: via reduce
val = comm.reduce(val, op=MPI.SUM, root=0)
# Console output
if rank == 0:
print(f"The sum of 1 to {N} is {val}.")Hello! I am process 1 of 1. I sum up 1 to 1000
The sum of 1 to 1000 is 500500.
We have now learned the most important communication mechanisms of MPI:
Point-to-point communication (
send,recv)Distribution of data (
bcast,scatter)Combining results (
gather,reduce)
With these building blocks, many parallel algorithms can already be implemented.