Parallelisierung
Vorbereitung¶
Aktuelle Entwicklungen in der Computertechnik gehen dahin, dass immer mehr Prozessoren in einem Rechner verbaut werden. Im derzeit laut top500.org leistungsstärksten Hochleistungsrechner, dem Frontier (Oak Ridge, USA), sind beispielsweise über 8 Millionen Rechenkerne verbaut. Eine solche Hardware wollen wir bei der Entwicklung effizienter Algorithmen ausnutzen.
Bisher liefen unsere Algorithmen mehr oder weniger sequentiell. Das bedeutet, unser Programm wird Zeile für Zeile auf einem einzelnen Rechenkern ausgeführt. Das Gegenstück zur sequentiellen Programmierung ist die parallele Programmierung.
Die Grundidee besteht darin, ein Problem in mehrere Teilprobleme zu zerlegen, die möglichst unabhängig voneinander und gleichzeitig von mehreren Recheneinheiten bearbeitet werden können. Die Teilergebnisse dieser Prozesse müssen anschließend zu einem Gesamtergebnis zusammengeführt werden. Ein zentraler Aspekt paralleler Programme ist daher die Kommunikation zwischen den Prozessen.
Wir installieren zunächst das benötigte Modul in unsere Conda-Umgebung:
conda install -c conda-forge mpi4pyMPI steht für Message Passing Interface. Dabei handelt es sich um eine standardisierte Schnittstelle, die Funktionen zur Kommunikation zwischen parallel laufenden Prozessen bereitstellt.
Testen wir zunächst, ob die Installation erfolgreich war. Dazu schreiben wir ein simples Programm
print("Hello world")Output
Hello world
und speichern dieses in einer Datei namens hello_world.py.
Um das Programm nun viermal parallel auszuführen, schreiben wir in die Konsole:
mpirun -np 4 python hello_world.pyWir erhalten folgende Ausgabe:
Hello world
Hello world
Hello world
Hello worldDies ist natürlich noch kein echtes paralleles Programm. Unser Skript wird lediglich viermal gleichzeitig gestartet.
Die Idee besteht nun darin, einen Algorithmus effizienter zu gestalten, indem wir das zugrunde liegende Problem in möglichst unabhängige Teilprobleme zerlegen, die parallel berechnet werden können. Idealerweise benötigen diese Teilprobleme nur wenig Kommunikation untereinander.
Wir erläutern die grundlegenden Konzepte an einem sehr einfachen Beispiel:
Diese Aufgabe lässt sich nahezu perfekt parallelisieren. Für beispielsweise könnte
Prozess 1 die Summe von 1 bis 25 berechnen,
Prozess 2 die Summe von 26 bis 50,
Prozess 3 die Summe von 51 bis 75,
Prozess 4 die Summe von 76 bis 100.
Die Zwischenergebnisse werden anschließend an einen Hauptprozess gesendet, der daraus das finale Ergebnis berechnet.
Formal ergibt sich für Prozesse folgende Darstellung:
Zur Vereinfachung nehmen wir zunächst an, dass durch teilbar ist.
Unser Programm soll also so aufgebaut sein, dass jeder Prozess die innere Summe berechnet, während der Hauptprozess anschließend die äußere Summe bildet.
Zur Kommunikation zwischen den einzelnen Prozessen wird ein sogenanntes Communicator-Objekt verwendet. Im folgenden Beispiel speichern wir den sogenannten World Communicator in der Variable comm. Mit diesem Objekt können wir sowohl den Rang eines Prozesses als auch die Gesamtanzahl aller Prozesse ermitteln:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
print(f"Hello! I am process {rank+1} of {size}.")Beim Ausführen mit
mpirun -np 4 python first_mpi_prog.pyerhalten wir beispielsweise folgende Ausgabe:
Hello! I am process 2 of 4.
Hello! I am process 1 of 4.
Hello! I am process 4 of 4.
Hello! I am process 3 of 4.Auffällig ist, dass die Reihenfolge der Ausgaben nicht festgelegt ist. Der Prozess, der zuerst die print-Anweisung erreicht, schreibt auch zuerst auf die Konsole.
In vielen Programmen muss daher unterschieden werden, ob der aktuelle Code vom Hauptprozess oder von einem Hilfsprozess ausgeführt wird. Dies kann man beispielsweise mit folgender Fallunterscheidung realisieren:
if rank == 0:
[Anweisungen für Hauptprozess]
else:
[Anweisungen für Hilfsprozesse]Der Hauptprozess ist typischerweise dafür zuständig,
Eingabedaten an die Hilfsprozesse zu verteilen,
Zwischenergebnisse einzusammeln und
das finale Ergebnis zu berechnen oder weiterzuverarbeiten.
Einfache Kommunikation mit Send und Recv¶
Die einfachste Form des Datenaustauschs zwischen zwei Prozessen ist eine sogenannte Point-to-Point-Kommunikation mit den Methoden comm.recv(...) und comm.send(...) des Communicator-Objekts. Aus der Code-Dokumentation entnehmen wir, dass die Funktionen mit folgenden Parametern aufgerufen werden:
comm.send(obj, dest, tag=0)
obj = comm.recv(buf=None, source=ANY_SOURCE, tag=ANY_TAG, status=None)Der sendende Prozess ruft also die Methode send auf. Die zu sendenden Daten werden dabei als erstes Argument obj übergeben. Das zweite Argument dest gibt den Rang des Empfängerprozesses an.
Der empfangende Prozess ruft zur gleichen Zeit die Methode recv auf, welche das empfangene Objekt als Rückgabewert liefert.
Häufig ist es außerdem sinnvoll, den Parameter tag zu setzen. Damit können Nachrichten mit einer bestimmten Kennung versehen werden, sodass beim Empfang gezielt nach bestimmten Nachrichten gefiltert werden kann. Für unsere Zwecke benötigen wir die übrigen Parameter zunächst nicht.
Es ist außerdem zu beachten, dass send und recv blockierende Operationen sind. Das bedeutet, dass das Programm an dieser Stelle wartet und erst zur nächsten Zeile übergeht, wenn das entsprechende Gegenstück die Daten empfangen bzw. gesendet hat.
Beide Funktionen existieren auch in einer nicht-blockierenden Variante namens isend und irecv. Auf diese werden wir hier jedoch nicht näher eingehen.
Testen wir diese Methoden an unserem Beispiel. Zunächst erfragt jeder Prozess seinen Rang und setzt abhängig davon den Start- und Endindex für die Summation, wie in der inneren Summe in (2). Anschließend löst jeder Prozess seine Teilaufgabe:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
N = 1000
# Parameter für jeden Prozess setzen
start_idx = rank*N//size+1
end_idx = (rank+1)*N//size
# Kurze Info
print("I am process", rank, "and I will sum up the numbers", start_idx, "to", end_idx)
# Lösung des Teilproblems
val = sum(range(start_idx, end_idx+1))
Nun muss der Hauptprozess alle Zwischenergebnisse einsammeln und diese aufsummieren. Der Hauptprozess ruft dazu -mal recv mit unterschiedlichen Quellen (source=1, 2, ..., size-1) auf. Jeder Hilfsprozess sendet sein Ergebnis mit der Methode send an den Hauptprozess (dest=0):
if rank == 0:
# Hauptprozess
for i in range(1, size):
tmp = comm.recv(tag=1, source=i)
val = val + tmp
else:
# Hilfsprozesse
comm.send(val, 0, tag=1)
if rank == 0:
print("The sum of 1 to", N, "is", val)Ausgabe:
I am process 3 and I will sum up the numbers 751 to 1000
I am process 1 and I will sum up the numbers 251 to 500
I am process 2 and I will sum up the numbers 501 to 750
I am process 0 and I will sum up the numbers 1 to 250
The sum of 1 to 1000 is 500500Der tag-Parameter ist sowohl in der send- als auch in der recv-Funktion optional. Bei Programmen mit mehreren Kommunikationsphasen ist er jedoch hilfreich, um sicherzustellen, dass sich auch die richtigen send- und recv-Aufrufe miteinander austauschen.
Die weitere Verarbeitung der Daten – in diesem Fall die Ausgabe des Ergebnisses auf der Konsole – erfolgt nur im Hauptprozess.
Beachte außerdem, dass das Endergebnis zunächst nur im Hauptprozess verfügbar ist. Falls das Gesamtergebnis auch auf den Hilfsprozessen benötigt wird, kann der Hauptprozess dieses wiederum an alle anderen Prozesse verteilen, beispielsweise mit send und recv.
Später lernen wir noch die Funktion bcast kennen, mit der sich solche Daten deutlich einfacher an alle Prozesse gleichzeitig verteilen lassen.
Aufgabenverteilung mit bcast und scatter¶
Wir wollen hier zwei weitere Funktionen kennenlernen:
obj = comm.bcast(obj, root=0)
obj = comm.scatter(sendobj, root=0)Die Broadcsat-Methode bcast sendet die gleichen Daten an alle Prozesse.
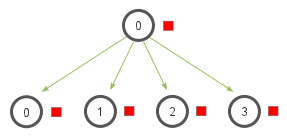
Broadcast
Wir könnten unser Programm beispielsweise so anpassen, dass das berechnete Endergebnis, welches zunächst nur dem Hauptprozess vorliegt, an alle anderen Prozesse gesendet wird. Eventuell wird dies benötigt, um die nächste Teilaufgabe in unserem Algorithmus zu starten.
In den meisten Fällen sendet der Hauptprozess mit Rang 0. Daher ist der Standardwert für den Parameter root meist ausreichend. Im Rückgabewert obj stehen anschließend die empfangenen Daten.
Wir ergänzen das obere Beispiel durch folgende Zeilen:
val = comm.bcast(val)
print("I am process", rank, "and I also know the answer:", val)Ausgabe:
I am process 0 and I also know the answer: 500500
I am process 1 and I also know the answer: 500500
I am process 2 and I also know the answer: 500500
I am process 3 and I also know the answer: 500500Beachte, dass die Variable val bereits in jedem Prozess definiert ist und in den Hilfsprozessen zunächst noch das Ergebnis der jeweiligen Teilaufgabe enthält. Dass der Wert in val vom Hauptprozess versendet wird, ist durch den Funktionsparameter root=0 festgelegt.
Ändert man die Zeile beispielsweise zu
val = comm.bcast(val, root=1)so würden alle Prozesse stattdessen das Zwischenergebnis vom Prozess mit Rang 1 empfangen.
Schauen wir uns nun die Methode scatter an.
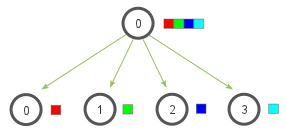
Scatter
Diese Methode kann verwendet werden, um vom Hauptprozess generierte Daten auf alle Prozesse aufzuteilen.
Diskutieren wir kurz die Ein- und Ausgabeparameter von scatter. Der erste Parameter sendobj muss im Hauptprozess eine Liste sein, in der das -te Element das Objekt ist, welches an den Prozess mit Rang gesendet werden soll.
In den Hilfsprozessen muss sendobj ebenfalls definiert werden; wir setzen hier einfach
sendobj = NoneDer zweite Parameter root mit dem Default-Wert 0 ist nur dann relevant, wenn die zu sendenden Daten von einem anderen Prozess als dem Hauptprozess kommen. In diesem Fall muss root den Rang dieses Prozesses enthalten.
Wir testen dies an folgendem Beispiel:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank==0:
sendobj = [i for i in range(size)]
print("sendobj:", sendobj)
else:
sendobj = None
obj = comm.scatter(sendobj)
print("I am process", rank, "and i received the data", obj)Ausgabe:
sendobj: [0, 1, 2, 3]
I am process 0 and i received the data 0
I am process 1 and i received the data 1
I am process 2 and i received the data 2
I am process 3 and i received the data 3Wir wollen die scatter-Funktion nun in unserem Summenbeispiel nutzen, um die Zeilen
start_idx = rank*N//size + 1
end_idx = (rank+1)*N//sizeetwas generischer zu gestalten.
Zwar kennt jeder Prozess die für ihn relevanten Parameter start_idx und end_idx bereits beim Start des Programms. Es gibt jedoch viele Situationen, in denen die für die Hilfsprozesse notwendigen Parameter erst zur Laufzeit bestimmt werden.
Beispielsweise könnten diese Parameter
von einer Nutzereingabe abhängen oder
vom Ergebnis eines vorherigen Schritts in unserem Algorithmus.
Wir ersetzen die beiden Zeilen daher durch folgenden Code:
if rank==0:
N = 10000
# Vorbereitung der Parameter für alle Prozesse
start_indices = [p*N//size+1 for p in range(size)]
end_indices = [(p+1)*N//size for p in range(size)]
# Liste aus Tupeln der Form (start_idx, end_idx) erstellen
sendobj = [(start_indices[p], end_indices[p]) for p in range(size)]
else:
sendobj = None
data = comm.scatter(sendobj, root=0)
# Parameter aus empfangenen Objekt extrahieren
start_idx = data[0]
end_idx = data[1]
# Kurze Info
print("I am process", rank, "and I will sum up the numbers", start_idx, "to", end_idx)Der Hauptprozess erstellt hier zunächst eine Liste mit den Parametern start_idx und end_idx für alle Prozesse. Das sendobj, welches auf die Prozesse verteilt wird, ist hier eine Liste, deren Elemente Tupel der Form (start_idx, end_idx) sind.
Die Hilfsprozesse extrahieren anschließend beide Parameter aus dem ihnen zugewiesenen Tupel und können mit der Lösung ihrer Teilaufgabe beginnen.
Prozesse zusammenführen mit reduce und gather¶
Eher suboptimal in unserem Beispiel ist die Art und Weise, wie die Zwischenergebnisse wieder an den Hauptprozess zur Weiterverarbeitung gesendet werden:
if rank == 0:
# Hauptprozess
for i in range(1, size):
tmp = comm.recv(tag=1, source=i)
val = val + tmp
else:
# Hilfsprozesse
comm.send(val, 0, tag=1)Die Ergebnisse werden hierbei nacheinander an den Hauptprozess gesendet. Für solche Situationen sind die Methoden reduce und gather meist besser geeignet.
Aus der Code-Dokumentation entnehmen wir folgende Aufrufe:
val = reduce(sendobj, op=MPI.SUM, root=0)
List = gather(sendobj, root=0)In beiden Fällen ist der erste Parameter sendobj das Objekt, welches das Zwischenergebnis jedes Prozesses enthält.
Der optionale Parameter root gibt an, welcher Prozess das Gesamtergebnis erhalten soll. Standardmäßig ist das der Prozess mit Rang 0.
Die Methode reduce benötigt zusätzlich den Parameter op. Dabei handelt es sich um eine Operation, welche auf die Zwischenergebnisse angewendet wird und daraus das Gesamtergebnis berechnet.
Die wichtigsten Operationen sind:
| Operation | Beschreibung |
|---|---|
MPI.SUM | Summiert alle Werte auf |
MPI.PROD | Multipliziere alle Werte auf |
MPI.MAX | Ermittle das Maximum aus allen Werten |
MPI.MAXLOC | Ermittle das Maximum und den Rang des zug. Prozesses |
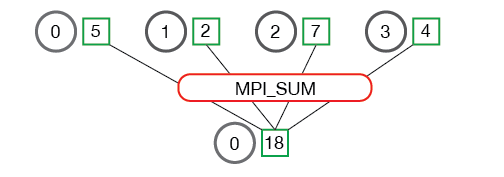
Reduce
Probieren wir diese Methode für unser Beispiel aus. Wir ersetzen den oben stehenden Code durch:
val = comm.reduce(val, op=MPI.SUM, root=0)Damit werden die Werte der Variable val aus allen Prozessen miteinander aufsummiert. Das Ergebnis wird im Prozess mit Rang 0 gespeichert.
Die Methode gather arbeitet etwas anders. Prinzipiell ist sie das Gegenstück zur scatter-Methode.
Während scatter eine Liste von Daten auf mehrere Prozesse verteilt, sammelt gather die Daten aller Prozesse ein und legt sie in einer Liste ab, welche vom root-Prozess weiterverarbeitet werden kann.
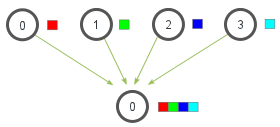
Gather
Auf unser Beispiel angewendet sieht das wie folgt aus:
all_vals = comm.gather(val)
if rank==0:
print(f"Gather gives me the following list: {all_vals}")
# Diese Liste aufsummieren
val = sum(all_vals)
print("The sum of 1 to", N, "is", val)Ausgabe:
Gather gives me the following list: [3126250, 9376250, 15626250, 21876250]
The sum of 1 to 10000 is 50005000.Der vollständige Code zur Lösung unseres Beispiels ist:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank==0:
N = 1000
# Start- und End-Indizes berechnen
start_indices = [int(p*N/size+1) for p in range(size)]
end_indices = [int((p+1)*N/size) for p in range(size)]
# In einer Liste sammeln
sendobj = [(start_indices[p], end_indices[p]) for p in range(size)]
else:
sendobj = None
# Indizes an Helfer-Prozesse schicken
data = comm.scatter(sendobj, root=0)
# Indizes entpacken
start_idx = data[0]
end_idx = data[1]
print(f"Hello! I am process {rank+1} of {size}. I sum up {start_idx} to {end_idx}")
# Lösung der Teilprobleme
val = sum(range(start_idx, end_idx+1))
# Senden der Daten an den Hauptprozess
# Option 1: Via send/recv
#if rank == 0:
# for i in range(1,size):
# tmp = comm.recv(source=i, tag=7)
# val = val + tmp
#else:
# comm.send(val, dest=0, tag=7)
# Option 2: Via gather
#all_vals = comm.gather(val, root=0)
#if rank==0:
# print(f"Gather gives me the following list: {all_vals}")
# val = sum(all_vals)
# Option 3: Via reduce
val = comm.reduce(val, op=MPI.SUM, root=0)
# Konsolenausgabe
if rank==0:
print(f"The sum of 1 to {N} is {val}.")Hello! I am process 1 of 1. I sum up 1 to 1000
The sum of 1 to 1000 is 500500.
Damit haben wir die wichtigsten Kommunikationsmechanismen von MPI kennengelernt:
Punkt-zu-Punkt-Kommunikation (
send,recv)Verteilung von Daten (
bcast,scatter)Zusammenführen von Ergebnissen (
gather,reduce)
Mit diesen Bausteinen lassen sich bereits viele parallele Algorithmen implementieren.