Microsoft® Dynamics™ AX   | ||||
 Einleitung Grundlagen ERP-Systeme Verkauf Einkauf / Beschaffung Produktion Versand Finanzwesen |   Die Datenbank
Wie sind die Daten innerhalb der Datenbank organisiert?
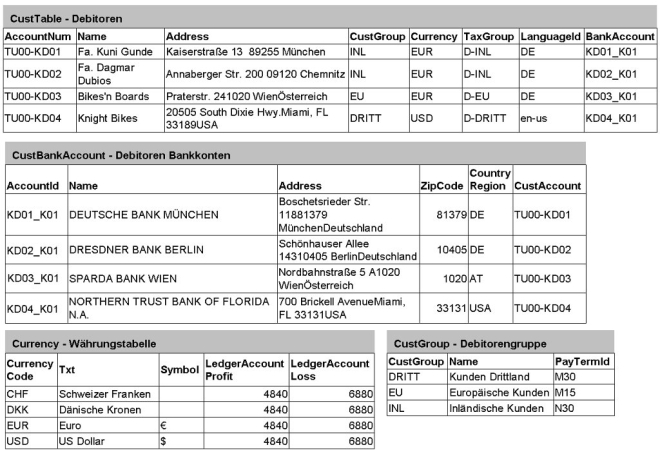
Informationen werden innerhalb einer Datenbank in Tabellen (Relationen) gespeichert. Wie diese aufgebaut sind soll an einem Beispiel aus Microsoft Dynamics AX gezeigt werden. Dazu betrachten wir einen Teilbereich aus der Debitorenverwaltung.
Eine Tabelle besteht aus diversen Datenelementen (Attributen), die die Informationen als Datensätze speichern. In obiger Abbildung enthält z.B. die Tabelle „CustTable“ Datenelemente für das Debitorenkonto(AccountNum), den Debitorennamen(Name), die Adresse(Address), die Bankverbindung(BankAccount) und so weiter. Diese Attribute können jeweils nur solche Werte speichern, die ihrem hinterlegten Datentyp entsprechen. Beispielsweise kann das Element „ZipCode“ in der Tabelle „CustBankAccount“ nur eine zehnstellige Zahl speichern, während das Feld „Address“ in der Tabelle „CustTable" eine bis zu 250 Stellen lange Zeichenkette aufnehmen kann. Daten aus verschiedenen Tabellen können logisch miteinander verknüpft sein. So ist z.B. der Datensatz der Firma Kuni Gunde aus der Tabelle „CustTable“ mit einem Datensatz der Tabelle „CustBankAccount“ verknüpft, der die zugehörigen Bankverbindungsdaten enthält. Außerdem lässt sich aus dem Datensatz für die Firma Kuni Gunde über den logischen Bezug des Datenelementes „CustGroup“ in der „CustTable“ auf die damit verknüpfte Zahlungsbedingung N30 aus der Tabelle „CustGroup“ schließen.
Wieso gibt es kontrollierte Redundanz? , ist ihnen aufgefallen, dass in der Abbildung der Tabellen redundante Einträge zu finden sind?So ist das Datenelement "AccountNum" in der Tabelle "CustTable" redundant in der Tabelle "CustBankAccount" als "CustAccount" gespeichert. Diese kontrollierte Redundanz ist aus Performanzgründen eingefügt worden. So ist z.B. davon auszugehen, dass beim Zugriff auf Bankverbindungsdaten eines Debitors innerhalb des ERP-Systems zusätzlich noch weitere Daten über den Kunden benötigt werden. Würde auf die Redundanz verzichtet, wäre ein Join über mehrere Tabellen nötig um diese Informationen zu erhalten. So kann einfach über den Schlüssel der Debitorennummer auf den entsprechenden Datensatz zugegriffen werden. Eine Inkonsistenz in den Datenbeständen wird durch das DBMS oder ERP-System verhindert, indem bei Änderungen auch die redundanten Einträge mit aktualisiert werden. Weitergehende Literatur
| |||