PBS ist sehr überlastet. Bitte nicht ständig qsub starten und beenden, falls qsub auf freie Ressourcen wartet.
Beispiel: nicht interaktiver Job
$ qsub -l nodes=5,walltime=0:01:00 -A URZ -M ronsc@hrz.tu-chemnitz.de hello_job.sh
39654.clic0a1.hrz.tu-chemnitz.de
PBS-Optionen im Scriptfile
$ cat hello_job.pbs
#!/bin/sh
#PBS -l nodes=5,walltime=0:01:00
#PBS -A URZ
#PBS -M ronsc@hrz.tu-chemnitz.de
# gehe zu allen Knoten und starte Task
$ qsub hello_job.pbs
39655.clic0a1.hrz.tu-chemnitz.de
Job-Identifikation über Job-Id
Job-ID: 39732.clic0a1.hrz.tu-chemnitz.de
nach Jobstart - während Job
qstat
$ qstat -n $PBS_JOBID
clic0a1.hrz.tu-chemnitz.de: CLiC - Chemnitzer Linux Cluster
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
39687.clic0a1.h ronsc parallel STDIN 11014 5 -- -- 01:00 R 00:14
clic3l13/0+clic3l12/0+clic3l11/0+clic3k43/0+clic3k42/0
$ qstat -f $PBS_JOBID
Job Id: 39687.clic0a1.hrz.tu-chemnitz.de
Job_Name = STDIN
Job_Owner = ronsc@odoaker.hrz.tu-chemnitz.de
resources_used.cput = 00:00:01
resources_used.mem = 9164kb
resources_used.vmem = 18960kb
resources_used.walltime = 00:14:48
job_state = R
queue = parallel24
server = clic0a1.hrz.tu-chemnitz.de
Account_Name = URZ
Checkpoint = u
ctime = Mon May 23 15:14:35 2005
Error_Path = /dev/ttyp0
exec_host = clic3l13/0+clic3l12/0+clic3l11/0+clic3k43/0+clic3k42/0
...
etime = Mon May 23 15:14:35 2005
Sub-Cluster (meine Rechenknoten)
- jeder Knoten hat lokales tmp-Verzeichnis (11GB)
/tmp wird nicht sofort gelöscht. Temporäre Dateien müssen so benannt sein, dass es keine Kollisionen gibt.
- AFS, z.B. Projektverzeichnis
Bitte nicht von allen Knoten aus im AFS arbeiten. Dies bringt den AFS-Server zum Erliegen.
- identische Installation (Hardware, Software)
- Umgebungsvariablen (nur auf Master-Knoten)
$ set | grep PBS
PBS_ENVIRONMENT=PBS_INTERACTIVE
PBS_JOBCOOKIE=3615E9184A04EECD452369577B517424
PBS_JOBID=39681.clic0a1.hrz.tu-chemnitz.de
PBS_JOBNAME=STDIN
PBS_MOMPORT=15003
PBS_NODEFILE=/var/spool/pbs/aux/39681.clic0a1.hrz.tu-chemnitz.de
PBS_NODENUM=0
PBS_O_HOME=/afs/tu-chemnitz.de/home/urz/r/ronsc
PBS_O_HOST=odoaker.hrz.tu-chemnitz.de
PBS_O_LANG=en_US.UTF-8
PBS_O_LOGNAME=ronsc
PBS_O_MAIL=/var/mail/ronsc
PBS_O_PATH=/afs/tu-chemnitz.de/home/urz/r/ronsc/bin:/usr/hei...
PBS_O_QUEUE=clicMainQ
PBS_O_SHELL=/bin/bash
PBS_O_WORKDIR=/afs/tu-chemnitz.de/home/urz/r/ronsc/PUBLIC/clic
PBS_QUEUE=parallel24
PBS_TASKNUM=1
| $PBS_JOBCOOKIE | Job-Cookie |
| $PBS_JOBID | eindeutige Job-Id |
| $PBS_NODEFILE | Liste der zugeordneten Knoten |
| $PBS_NODEFILE.[lam|mpich].[eth0|eth1] | Knotenliste für versch. Bibliotheken |
Es sind keine Limits auf den Knoten gesetzt. Falls zu viel Speicher oder Festplatte genutzt werden, können Fehlverhalten oder Abstürze auftreten.
Arbeit mit den Knoten
- Knoten testen
$ clic_chk_hosts $PBS_NODEFILE
n0: clic3l13 : OK
n1: clic3l12 : OK
n2: clic3l11 : OK
n3: clic3k43 : OK
n4: clic3k42 : OK
- pbsdsh
$ pbsdsh hostname
clic3l13.hrz.tu-chemnitz.de
clic3l12.hrz.tu-chemnitz.de
clic3l11.hrz.tu-chemnitz.de
clic3k43.hrz.tu-chemnitz.de
clic3k42.hrz.tu-chemnitz.de
pbsdsh leitet keine AFS-Tokens weiter.
$ pbsdsh tokens
Tokens held by the Cache Manager:
--End of list--
Tokens held by the Cache Manager:
--End of list--
Tokens held by the Cache Manager:
User's (AFS ID 21866) tokens for afs@tu-chemnitz.de [Expires Jun 1 10:45]
--End of list--
Tokens held by the Cache Manager:
User's (AFS ID 21866) tokens for afs@tu-chemnitz.de [Expires Jun 1 10:45]
--End of list--
Tokens held by the Cache Manager:
User's (AFS ID 21866) tokens for afs@tu-chemnitz.de [Expires Jun 1 10:45]
--End of list--
- ssh
$ for host in `cat $PBS_NODEFILE` ; do ssh $host hostname ; done
clic3l13.hrz.tu-chemnitz.de
clic3l12.hrz.tu-chemnitz.de
clic3l11.hrz.tu-chemnitz.de
clic3k43.hrz.tu-chemnitz.de
clic3k42.hrz.tu-chemnitz.de
- mpi, pvm und Co.
Job beenden
- bei interaktiven Jobs: ausloggen, Ctrg-D
- bei nicht interaktiven Jobs: qdel <job-id>
$ qdel 39732
Manchmal wirkt qdel nicht sofort. Bitte den PBS-Server nicht mit qdel-Anfragen "fluten".
- qsig
$ qsig -h
usage: qsig [-s signal] job_identifier...
- Ausgaben des Jobs liegen <script-name>.o<job-id>, <script-name>.e<job-id>
$ ls -ltr
total 5
-rwxr-xr-x 1 ronsc urz 51 May 23 14:39 hello.sh
-rwxr-xr-x 1 ronsc urz 87 May 23 14:43 hello_job.sh
-rwxr-xr-x 1 ronsc urz 150 May 23 14:44 hello_job.pbs
-rw------- 1 ronsc urz 155 May 23 14:49 hello_job.sh.o39654
-rw------- 1 ronsc urz 0 May 23 14:49 hello_job.sh.e39654
Falls der Job die Ausgaben nicht abspeichern kann, so werden diese als "undelivered" unter /afs/tucz/project/cluster/undelivered abgespeichert.
Subject: [CLiC-Admins] [CLiC:] found undelivered files on clic4l41
Please have a look at this/these archive file(s):
Bitte schauen Sie sich das/die Archiv(e) an:
---begin---------------------------------------------------------------------
/afs/tucz/project/cluster/undelivered/thpo/undelivered.39745.clic0.ER.gz
(archive includes)
file name = 39745.clic0.ER
rights = -rw-------
owner = thpo
group = user
size = 0
access date = May 24 10:42
/afs/tucz/project/cluster/undelivered/thpo/undelivered.39745.clic0.OU.gz
(archive includes)
file name = 39745.clic0.OU
rights = -rw-------
owner = thpo
group = user
size = 0
access date = May 24 10:42
---end-----------------------------------------------------------------------
If your file(s) is/are in directory:
/afs/tucz/project/cluster/undelivered/thpo
and you may have sighted your file(s) please remove it from directory.
Ist/sind Ihr(e) File(s) im Verzeichnis:
/afs/tucz/project/cluster/undelivered/thpo
und Sie haben es/sie möglicherweise gesichtet, entfernen Sie es/sie
bitte aus dem Verzeichnis.
Yours sincerely / Mit freundlichen Grüßen
clic-admins@tu-chemnitz.de (from clic4l41)
Inhalt
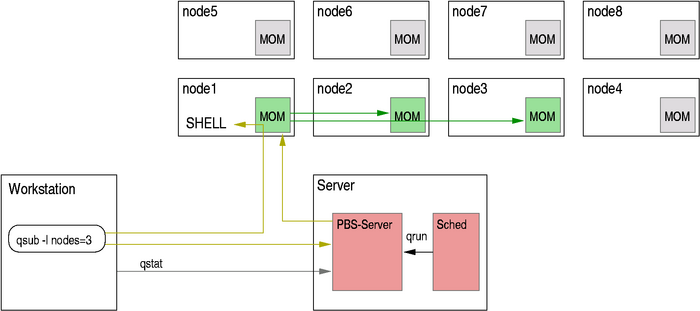
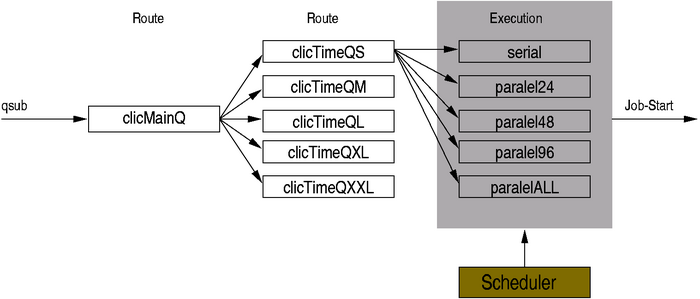 Die Anzahl gleichzeitig laufender Jobs pro Nutzer sind beschränkt.
Die Anzahl gleichzeitig laufender Jobs pro Nutzer sind beschränkt.