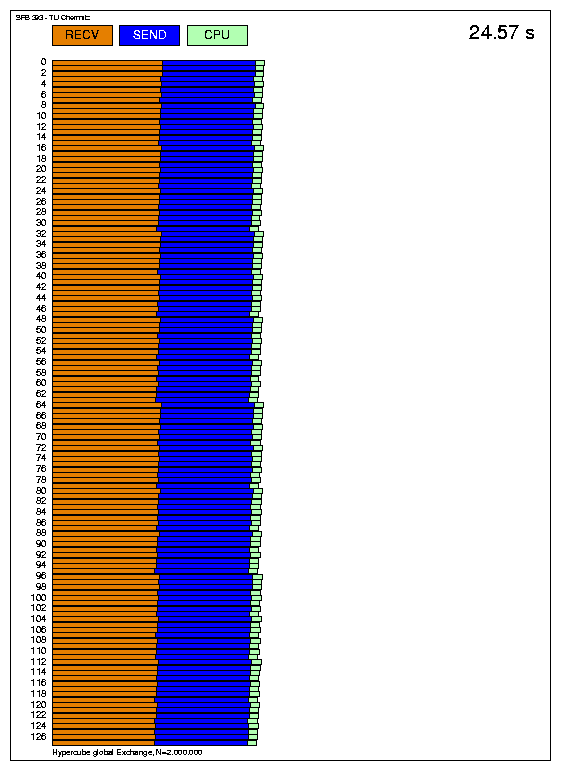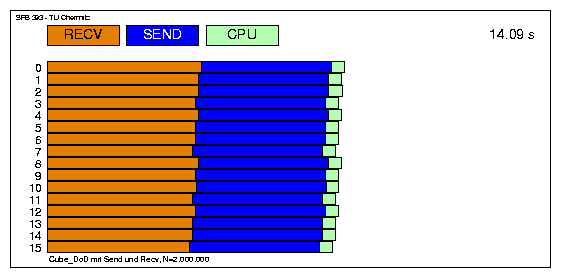
Variante mit MPI_send und MPI_recv (Austausch in jedem Schritt, Hypercube):
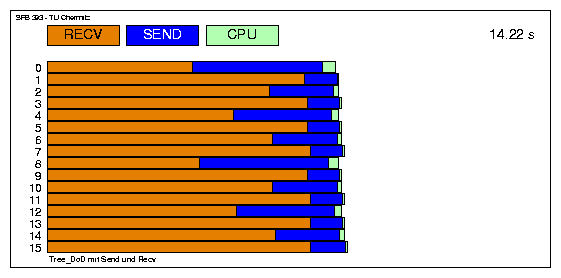
Variante mit MPI_send und MPI_recv (baumartige Kommunikation: Tree_Up/Tree_Down):
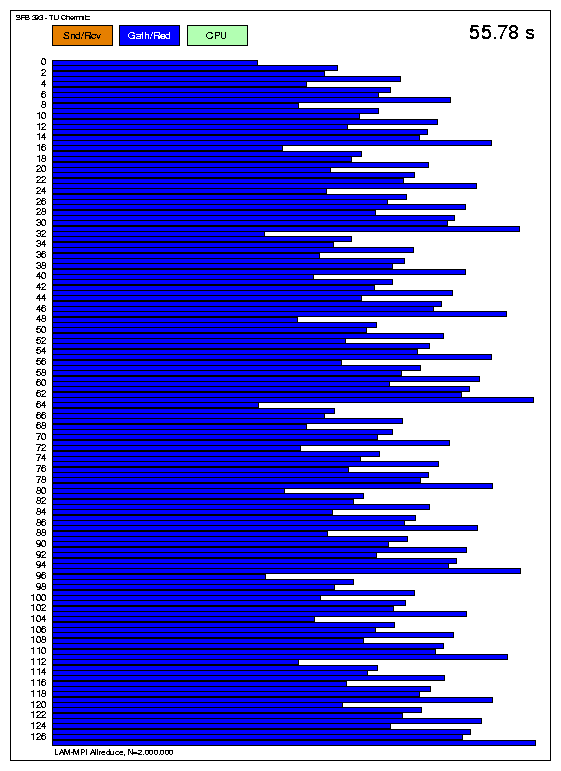
Variante mit MPI_Allreduce
Die Implementierung dieser Routine ist bei LAM-MPI offenbar nicht gut gelungen.
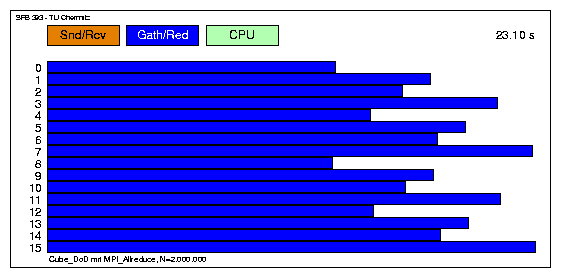
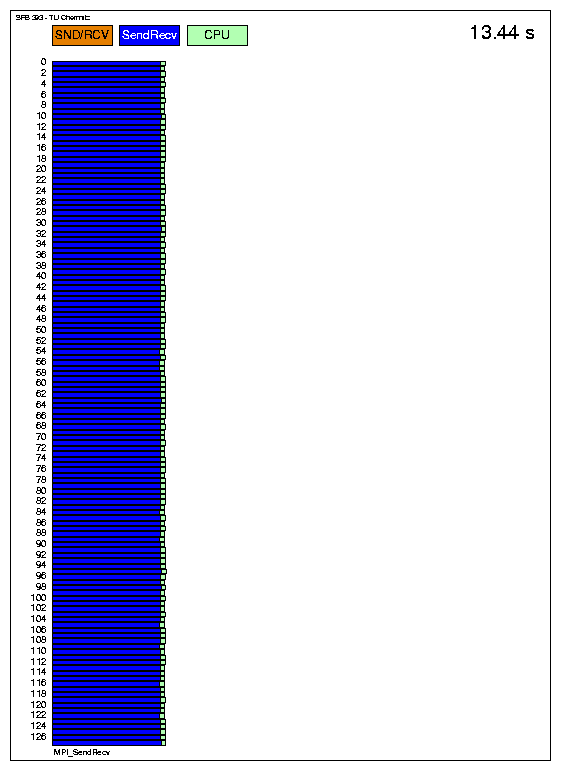
Auch für 128 Prozessoren sieht der Vergleich ähnlich aus. Das dritte Diagramm zeigt die Zeiten, die mit MPI_sendrecv erhalten wurden, also nahezu eine Halbierung der Transferzeiten gegenüber der Version mit MPI_send und MPI_recv.