 |
Einführung in Betriebssysteme
von Prof. Jürgen Plate |
2 Prozesse
2.1 Programme, Prozeduren, Prozesse und Instanzen
Programm:
Die Lösung einer Programmieraufgabe (=Algorithmus) wird in
Form eines Programms realisiert. Teillösungen werden
dabei als Prozeduren (Unterprogramme) formuliert, welche
nach Beendigung ihrer Arbeit zum aufrufenden
übergeordneten Programm zurückkehren. Damit die Leistungen des
Betriebssystemkerns problemlos in Anwenderlösungen eingebunden
werden können, sind sie ebenfalls als Prozeduren realisiert.
Ein Programm (Prozedur, Unterprogramm) besteht aus:
- Befehlen (Codebereich, Textbereich)
- Programmdaten (Datenbereich)
Beide Komponenten sind problemorientiert.
Prozeß:
Wird ein Programm (Prozedur) unter der Kontrolle eines Betriebssystems (genauer
gesagt unter der Kontrolle eines Betriebssystemkerns) ausgeführt, so wird dieser
Ablauf als Prozeß (engl. Task) bezeichnet.
Diese Betrachtungsweise macht es möglich, daß mehrere Programme gleichzeitig als
Prozesse parallel auf einem sequentiell arbeitenden Rechnersystem
(unabhängig von der realen Anzahl Prozessoren) ablaufen können.
Als Sonderfall gilt die Ausführung mehrerer Prozesse auf einem Prozessor.
Bei der Ausführung von Prozessen entstehen Daten, die durch den Betriebssystemkern
verwaltet werden. Diese werden Statusinformationen genannt und sind systemabhängig,
z. B. Registerinhalte.
Die Funktionalität des Betriebssystemkerns bezüglich der Verwaltung von Prozessen ist
bei der Ausführung von n Prozessen auf einem Prozessor äquivalent der Verwaltung
auf m > 1 Prozessoren. Dabei kann das Verhältnis m : n sowohl statisch
als auch dynamisch änderbar sein.
Als weitere Komponente wird beim Ablauf eines Programms ein Kellerspeicher (Stack)
aufgebaut. Somit läßt sich ein Prozeß modellhaft folgendermaßen darstellen.
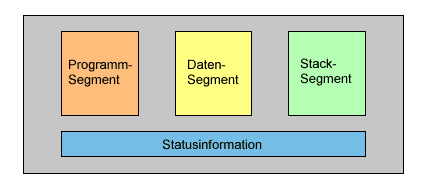
Alle vier Komponenten, die bei der Ausführung eines Programms (einer Prozedur) beteiligt
sind, werden als Instanz zusammengefaßt.
Instanz:
Eine Instanz umfaßt das Tupel (C, D, S, I):
| C: | Codesegment | --> | problemorientiert |
|---|
| D: | Datensegment | --> | problemorientiert |
|---|
| S: | Stacksegment | --> | system-/problemorientiert |
|---|
| I: | Statusinformation | --> | systemorientiert |
|---|
Die physische Anordnung dieser Komponenten im Arbeitsspeichers eines Rechners kann in
unterschiedlichen Betriebssystemen verschieden sein.
Wir halten also fest:
Prozeßmodell
- Ein Prozeß ist ein Programm während der Ausführung
(Für uns gleichbedeutend mit "Task". Es gibt jedoch BS, bei denen
ein Programm mehrere Prozesse startet, einen solchen Prozeß nennt man dann
"Thread".)
- Es können sich mehrere Prozesse gleichzeitig im Speicher befinden, es
ist jedoch immer nur ein Prozeß aktiv, d.h. er wird von der Hardware bearbeitet
(außer es gibt mehrere CPUs) --> parallel falls die Zahl der
Prozessoren größer oder gleich der Zahl der Prozesse ist, quasiparallel
im anderen Fall.
- Ein Teil des BS, der Scheduler, wählt einen Prozeß aus, teilt ihm
die CPU zu und läßt ihn eine gewisse Zeit rechnen.
Moderne Rechner können mehrere Dinge gleichzeitig ausführen. Unterstützt
durch die Hardware lassen sich einzelne Aufgaben des BS parallelisieren. z. B.
das Ausgeben einer Datei auf dem Drucker, während das Programm weiterläuft
(auch im Einprogrammbetrieb!). Es gibt also in der Regel parallele Arbeit von CPU
und E/A-Geräten.
Im Mehrprogrammbetrieb wird jedem Programm einen kurzen Zeitabschnitt (Zeitscheibe)
lang die CPU zugeteilt, wodurch die Benutzer die Illusion erhalten, alle Programme
würden gleichzeitig bearbeitet --> Pseudoparallelität. Damit lassen
sich folgende Eigenschaften von Prozessen definieren:
- Jeder Prozeß besitzt seine eigene Prozeßumgebung (Instanz).
- Jeder Prozeß kann seinerseits andere Prozesse erzeugen und - mit Hilfe
der BS-Kerns - mit anderen Prozessen kommunizieren.
- Prozesse können voneinander abhängen --> kooperierende Prozesse.
Derartige Prozesse müssen sich untereinander synchronisieren.
- Prozessen kann eine Priorität zugeordnet werden, aus der sich die
Reihenfolge ergibt, mit der die Prozesse der CPU zugeteilt werden.
- Die Speicherung der Prozeßzustände erfolgt in einer vom BS
geführten Prozeßtabelle.
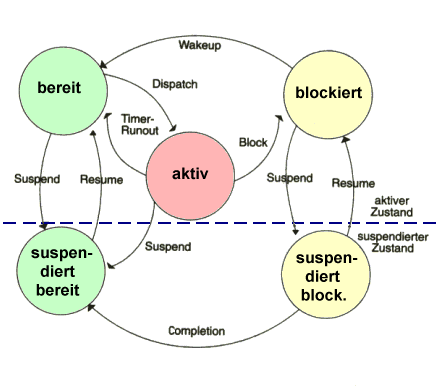
2.2 Prozeßzustände
Während seiner Abarbeitung kann ein Prozeß verschiedene Zustände
einnehmen:
- aktiv (running): Prozeß wird von der CPU bearbeitet
- bereit (ready): Prozeß kann die CPU benutzen, ist aber durch einen anderen
Prozeß verdrängt worden
- blockiert: Prozeß wartet auf das Eintreten eines bestimmten Ereignisses
(z. B. Drucker bereit, Benutzereingabe, etc.)
Der Einfachheit halber wird hier ein Rechnersystem mit nur einer CPU angenommen,
d. h. ein Prozeß ist aktiv, alle anderen sind bereit oder blockiert.
- Für bereite und blockierte Prozesse wird jeweils eine separate Warteliste
geführt.
- Ein neu gestartetes Programm wird am Ende der Bereit-Liste eingetragen.
- Ein spezieller Teil des Betriebssystems, der Scheduler, teilt den Prozessen
die CPU zu. Für die Zuteilung existieren unterschiedliche Algorithmen, die
alle das Ziel haben, die CPU möglichst gerecht unter allen Prozessen aufzuteilen.
Für die Steuerung der Zeitscheiben ist ein in regelmäßigen Zeitabständen
auftretender Harwareinterrupt notwendig --> Scheduler wird regelmäßig
aufgerufen.
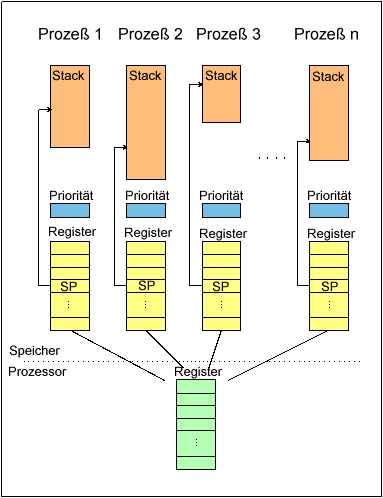
Die Situation in der Hardware stellt sich etwa folgendermaßen dar. Im Speicher liegen
die einzelnen Instanzen der Prozesse. Jeweils ein Prozeß wird der CPU zugeteilt.
Zustandswechsel eines Prozesses:
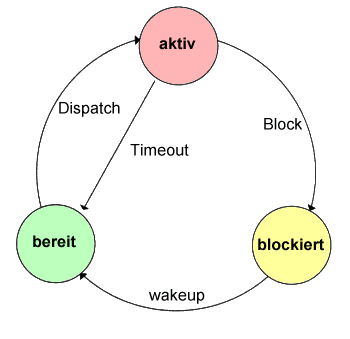
- Dispatch: bereit --> aktiv
Zuteilung der CPU an einen Prozeß.
- Timerrunout: aktiv --> bereit
Nach Ablauf einer Zeitscheibe wird dem Prozeß die CPU wieder entzogen.
- Block: aktiv --> blockiert
Aktiver Prozeß hat eine E/A-Operation angefordert (oder sich selbst für
eine bestimmte Zeit verdrängt), bevor seine Zeitscheibe abgelaufen war.
Dies ist der einzige Zustandswechsel, den ein Prozeß selbst auslösen kann.
- Wakeup: blockiert --> bereit
Das Ereignis, auf das der Prozeß gewartet hat ist eingetreten.
Signal an den Prozeß
Zu jedem Prozeß legt das BS einen Prozeßsteuerblock (process control
block = PCB) in der Prozeßtabelle ab, der alle notwendigen Informationen
über einen Prozeß enthält, z. B.:
- PID (Process ID) - dies ist eine eindeutige ganze Zahl, über die der Prozeß im
System identifiziert wird
- Prozeßzustand
- Verweise auf die dem Prozeß zugeteilten Speicherseiten
- Benutzerkennungen (die die Rechte des Prozesses bestimmen)
- Blockierursachen bei einem schlafenden Prozeß
- Identifikation empfangener, aber noch nicht bearbeiteter Signale
- etc.
Zusätzlich zum PCB werden noch weitere, zum Prozeß
gehörige Daten geführt, auf die er aber nur im Zustand "running"
Zugriff hat. Dazu gehören:
- Eine Tabelle, in der die Reaktion des Prozesses auf jedes mögliche
Signal festgelegt ist
- Verweis auf das zugeordnete Terminal
- Verweis auf das aktuelle Inhaltsverzeichnis
- Die Tabelle der Dateideskriptoren
- Eine Bitmaske, die die Zugriffsrechte von Dateien mitbestimmt, die vom
jeweiligen Prozeß erzeugt werden
- etc.
2.3 Prozeßhierarchie und Prozeßrechte
Ein Prozeß kann einen neuen Prozeß starten (fork, spawn); ein solcher
Prozeß heißt "Kindprozeß" oder "Sohnprozeß"
(child process) und der Erzeuger-Prozeß wird "Elternprozeß"
oder "Vaterprozeß" (parent process) genannt.
- Jeder Kindprozeß hat genau einen Elternprozeß
- Ein Elternprozeß kann mehrere Kindprozesse besitzen
- Eltern- und Kindprozeß können miteinander kommunizieren
- Wird ein Elternprozeß beendet, beenden sich normalerweise auch alle seine Kindprozesse
Die Prozeßrechte sollen anhand des Betriebssystems UNIX erläutert
werden. Jeder Prozeß hat im Verlauf seiner Existenz zwei Benutzeridentifikationen:
Die "reale" Benutzer-ID bezeichnet den Benutzer, der für den Ablauf
des Prozesses verantwortlich ist. Sie bleibt in der Regel konstant. Die
"effektive" Benutzer-ID kann sich jedoch beliebig oft ändern und bestimmt
jeweils die momentanen Rechte des Prozesses in Bezug auf Dateizugriffe
und andere Mechanismen, die benutzerabhängigen Einschränkungen
unterliegen.
Die Änderung der effektiven Benutzer-ID kann auf zweierlei Art erfolgen:
Wenn der Prozeß ein Programm eines anderen Benutzers ausführen möchte,
dann prüft das Betriebssystem zuerst seine Berechtigung dazu (über
die entsprechenden Dateizugriffsrechte). Falls die Zugriffsrechte der Programmdatei
außerdem das sogenannte "setuid-Bit" enthalten, dann wird die effektive
Benutzer-ID des Prozesses mit der Eigentümerkennung des aufgerufenen
Programms überschrieben, und der Prozeß hat demzufolge
jetzt die Rechte des Eigentümers des Programms.
Die zweite Möglichkeit zur Veränderung der effektiven Benutzer-ID
ist der explizite Aufruf der Systemfunktion setuid(). So ist es möglich,
die effektive Benutzer-ID so zu verändern,
daß sie den Wert der realen Benutzer-ID erhält oder den Wert der
effektiven Benutzer-ID, die der Prozeß bei seiner Aktivierung von seinem
Vater "geerbt" hat.
2.4 Prozeß-Operationen des BS
Aus dem bisher gesagten kann man bestimmte Operationen ableiten, die das Betriebssystem
zur Steuerung und Kontrolle von Prozessen ausführt. Die wichtigsten
Prozeß-Operationen sind in der folgenden Tabelle zusammengefaßt.
| Create | Erzeugen eines Prozesses (z.B. Laden eines Programms)
- Vergabe einer PID, Anlegen eines PCB in der Prozeßtabelle
- Allokieren des benötigten Speichers
- Reservieren der benötigten Ressourcen
- Vergabe einer Priorität
|
| Kill | Löschen eines Prozesses
- Löschen aller Einträge aus den Systemtabellen
- Freigabe von Speicher und Ressourcen (z.B. Dateien schließen)
- Löschen aller Abkömmlinge (Kindp., Enkelp., usw.)
|
| Suspend | Suspendieren eines Prozesses
- Suspendierung normalerweise nur bei Systemüberlastung durch Prozesse
höherer Priorität, Wiederaufnahme erfolgt sobald möglich.
|
| Resume | Wiederaufnehmen eines suspendierten Prozesses
- Suspendierung normalerweise nur bei Systemüberlastung durch Prozesse
höherer Priorität, Wiederaufnahme erfolgt sobald möglich.
|
| Block | Blockieren eines Prozesses |
| Wakeup | Aufwecken eines blockierten Prozesses |
| Dispatch | CPU an einen Prozeß zuteilen |
| Change | Priorität eines Prozesses ändern |
In der Tabelle wird erstmals die Möglichkeit der "Suspendierung" eines Prozesses
aufgeführt. Wird das System durch Prozesse höherer Priorität überlastet
(kein Speicher mehr frei, keine Dateihandles mehr frei, Prozesstabelle voll, etc.),
müssen Prozesse aus dem Speicher entfernt und z. B. auf die Platte ausgelagert werden.
Im einfachsten Fall reicht auch manchmal die Auslagerung eines Eintrags in der
Prozeßtabelle in eine andere Tabelle. Sobald sich die Situation entspannt hat, wird
der Prozeß wieder in den alten Stand zurückversetzt. Bei der Suspendierung wird
man natürlich solche Prozesse zuerst auslagern, die sowieso auf ein Ereignis warten.
Durch die Suspendierungsmöglichkeit erweitert sich das Diagramm der
Prozeßzustände:
2.5 Prozeß-Synchronisation
In einigen Multitasking-Betriebssystemen teilen sich verschiedene Prozesse
gemeinsame Betriebsmittel. Bei gleichzeitigem Zugriff zweier Prozesse auf diese
Betriebsmittel kann es zu Inkonsistenzen der Daten kommen, die u. U. selten auftreten
und sehr schwer aufzuspühren sind.
Kooperierende nebenläufige Prozesse müssen daher wegen der zwischen ihnen
vorhandenen Abhängigkeiten miteinander synchronisiert (koordiniert) werden.
Prinzipiell lassen sich zwei Klassen von Abhängigkeiten unterscheiden:
- Die Prozesse konkurieren um die Nutzung gemeinsamer, exklusiv nutzbarer Betriebsmittel
Beispiel: Zwei Prozesse greifen verändernd auf gemeinsame Daten zu. Der Zugriff zu
den gemeinsamen Daten muß koordiniert werden, um eine Inkonsistenz der Daten zu
vermeiden --> Sperrsynchronisation (gegenseitiger Ausschluß, mutual exclusion)
- Die Prozesse sind voneinander datenabhängig.
Beispiel: Ein Prozeß erzeugt Daten, die von einem anderen Prozeß weiter
bearbeitet werden sollen. Es muß eine bestimmte Abarbeitungsreihenfolge
entsprechender Verarbeitungsschritte eingehalten werden --> Zustands- oder
Ereignissynchronisation (z. B. Produzenten-Konsumenten-Synchronisation)
Ohne eine solche Sperrung entstehen Datenverluste, z. B. in folgenden Fall:
- Prozeß A und Prozeß B lesen ein Datenelement im Zustand X(0).
- A schreibt es mit dem Wert X(1) zurück,
- danach schreibt B seinen Wert X(2) zurück.
Damit bleibt die Änderung X(0) nach X(1) aus dem Prozeß A
unberücksichtigt.
Oder auch bei folgendem Beispiel:
- Prozeß A informiert sich in der Spooler-Warteschlange über den
nächsten freien Eintrag und notiert dessen Adresse, z. B. 7 in der Variablen
next_free_slot. Danach wird ihm der Prozessor entzogen.
- Prozeß B findet die gleiche Adresse (7) und trägt sie in
next_free_slot ein. Danach schreibt er an die Position 7 der Warteschlange
den Namen der auszugebenden Datei und erhöht die Variable next_free_slot
auf 8.
- Prozeß A erhält nun den Prozessor wieder zugeteilt und macht dort weiter,
wo er unterbrochen wurde. Er findet in next_free_slot den Wert 7 und
trägt den Namen der von ihm auszugebenden Datei in Position 7 der
Spooler-Warteschlange ein und erhöht die Variable next_free_slot
ohne zu bemerken, daß der Wert 8 dort schon eingetragen war.
Folge: Prozeß A überschreibt den Dateinamen, den Prozeß B
in der Spooler-Warteschlange auf Position 8 eingetragen hatte.
Diese Datei wird vom Spooler "vergessen".
Solche Situationen heißen zeitkritsche Abläufe.
Programmabschnitte, die auf gemeinsam benutzte Daten zugreifen, heißen
kritische Abschnitte.
Fehler in zeitkritischen Abläufen sind sehr schwer erkennbar, da sie nur sehr
selten auftreten. Sie können nur durch wechselseitigen Ausschluß vermieden
werden. Kritische Abschnitte treten überall auf, wo zwei oder mehr Prozesse auf
einem Computer oder in einem Netz um mindestens eine Ressource konkurrieren,
die sie schreibend benutzen wollen. Kritische Abschnitte können aber auch
überall da auftreten, wo mehrere Prozesse um eine Ressource konkurrieren, die
sie schreibend benutzen. Das trifft besonders auf Datenbankserver zu
(z. B. Reservierungssysteme, zentrale Karteien, usw.).
Vier Bedingungen für eine gute Lösung (nach Tanenbaum):
- Höchstens ein Prozeß darf sich in einem kritischen Abschnitt
aufhalten. (Korrektheit)
- Es dürfen keine Annahmen über Ausführungsgeschwindigkeit und
Anzahl der Prozessoren gemacht werden.
- Kein Prozeß, der sich in einem kritischen Abschnitt befindet, darf
andere blockieren.
- Kein Prozeß soll unendlich lange warten müssen,
bis er in einen kritischen Bereich eintreten darf.
Die letzten beiden Punkte dienen der Stabilität, sie sollen Prozeßverklemmungen
verhindern.
Beispiele für zeitkritische Abläufe
1. Das Erzeuger-Verbraucher-Problem:
Der Erzeuger E stellt ein Produkt her und stellt es in einen begrenzten Pufferspeicher.
Verbraucher V entnimmt dem Puffer ein Stück des Produktes, um es zu verbrauchen.
Beides geschieht zu zufälligen Zeitpunkten. Der Puffer wird von beiden gemeinsam
verwaltet. Solche Erzeuger-Verbraucher-Probleme treten beispielsweise bei Pipes auf
(Ein Prozeß erzeugt Daten, der andere verarbeitet sie weiter.)
- Der Erzeuger muß zuerst prüfen, ob noch Platz im Puffer ist, bevor
er ein Produkt ablegen kann.
Er muß dann auch den Produktzähler count erhöhen.
Ist der Puffer voll, muß er schlafen gehen.
- Der Verbraucher muß prüfen, ob der Puffer nicht leer ist, bevor er
etwas entnimmt. Er muß dann count dekrementieren. Ist nichts im Puffer,
muß er schlafen gehen.
Wenn der Erzeuger ein Produkt in den Puffer stellt, muß er den Verbraucher wecken.
Analog muß der Verbraucher den Produzenten wecken, wenn er ein Produkt aus dem
Puffer entnimmt. Tanenbaum verwendet dafür die Funktionen SLEEP und
WAKEUP. Er zeigt eine Lösung für das Erzeuger-Verbraucher-Modell,
die einen fatalen Fehler zuläßt:
#define N 100 /* Puffergröße */
int count = 0; /* Tatsächlicher Pufferinhalt */
void producer (void)
}
tinhalt item;
while (1) /* Endlosschleife */
}
produce_item (&item); /* Erzeuge 1 Stück */
if (count == N) SLEEP(); /* Falls Puffer voll, schlafen */
enter_item (item); /* lege erzeugtes Stück in Puffer */
count++;
/* wenn Puffer vor dem Weiterzählen leer war, Verbraucher wecken */
if (count == 1) WAKEUP(consumer);
}
}
void consumer (void)
}
tinhalt item;
while (1) /* Endlosschleife */
}
if (count == 0) SLEEP(); /* Falls Puffer leer, schlafen */
remove_item (item); /* entnehme dem Puffer ein Stück */
count--; /* Pufferinhalt korrigieren */
/* wenn Puffer vor Korrigieren voll war, Erzeuger wecken */
if (count == N-1) WAKEUP(producer);
consume_item (&item); /* verbrauche 1 Stück */
}
}
Die Funktionen sollen selbstständig laufende Programme repräsentieren,
die beide zu beliebigen Zeitpunkt durch einen Scheduler-Eingriff unterbrochen
oder wieder aktiviert werden können.
Wenn der Consumer schläft, weil der Puffer leer ist, muß man nicht
davon ausgehen, daß der Puffer immer leer bleibt. Der Producer kann ja
zwischendurch den Prozessor zugeteilt bekommen, etwas in den Puffer legen und
den Consumer wieder wecken.
Umgekehrt schläft der Producer, wenn der Puffer voll ist. Während er
schläft, kann der Consumer den Prozessor zugeteilt bekommen, etwas verbrauchen
(so daß im Puffer wieder Platz wird) und den Producer wieder wecken.
Der Fehler tritt bei folgendem Szenario auf:
Der Puffer ist leer und der Verbraucher stellt das fest (count = 0).
Genau jetzt unterbricht der Scheduler den Verbraucher und startet den Produzenten.
Dieser legt ein Produkt in den Puffer, setzt count auf 1 und startet WAKEUP.
Wenn der Verbraucher vom Scheduler wieder die CPU zugeteilt bekommt, ist er noch
wach. Der Weckruf verhallt ungehört, weil ja der Verbraucher nicht schläft.
Der Verbraucher wertet die vorher festgestellte Tatsache "count = 0" aus und geht
schlafen. Es gibt für den Produzenten keinen Anlaß, nochmals zu wecken.
Der Verbraucher wird nie mehr geweckt.
Ursache für diese Blockierung ist eine Prozeßunterbrechung im kritischen
Abschnitt zwischen Erkennung der Bedingung, die zum Aufruf von SLEEP führt
und dem SLEEP-Kommando selbst. Die gleiche Situation würde auftreten, wenn der
Produzent zwischen der Erkenntnis, daß der Puffer voll ist (free = 0) und dem
Schlafengehen unterbrochen wird.
2. Das Problem des schlafenden Friseurs:
Dieses Modell geht davon aus, daß beide nach dem Zeitscheibenprinzip nur
abwechselnd handeln können.
Ein Friseur bedient, sobald er Zeit dafür hat, ankommende oder wartende Kunden.
Der Warteraum ist beschränkt auf N Stühle.
- Der Friseur (= Prozessor) startet zu Arbeitsbeginn die Funktion barbier().
Wenn kein Kunde da ist, legt er sich schlafen.
- Kommt ein Kunde, prüft er die Bedingung count >= N. Sind
alle Stühle belegt, geht er wieder. Sonst bleibt er und erhöht count
um eins. War count vorher 0, weckt er den schlafenden Friseur.
- Wenn der Friseur einen Kunden bedient hat, dekrementiert er count.
Ist count dann 0 geworden, legt er sich wieder schlafen.
Die kritische Situation besteht darin, daß der Kunde zwischen der Dekrementierung
von count und der Frage "Ist count gleich 0" ankommt und den Friseur
wecken kann, obwohl der sich noch gar nicht schlafen gelegt hat.
Lösungsversuche für das Problem der kritischen Abschnitte
- Einfachste Lösung: Vor Eintritt in den kritischen Bereich alle
Interrupts sperren und sie nach Verlassen des kritischen Bereichs wieder
freigeben. Damit kann der Scheduler nicht während des kritischen Abschnitts
den Prozeß unterbrechen.
Nachteil: Kein verdrängendes Multitasking mehr. Der Anwenderprozeß kann
den Scheduler blockieren (gewollt oder ungewollt durch einen Programmfehler).
- Verfahren mit gegenseitigem Ausschluß
Der Programmabschnitt, in dem ein Zugriff zu dem nur exklusiv nutzbaren Betriebsmittel
(z. B. die gemeinsamen Daten) erfolgt, wird kritischer Abschnitt genannt. Es muß
verhindert werden, daß sich zwei Prozesse gleichzeitig in ihren kritischen
Abschnitten befinden.
- Sperrvariable:
Es wird eine logische Variable geführt, die mit 0 den Eintritt in den
kritischen Bereich erlaubt und mit 1 sperrt. Der in den kritischen Bereich
eintretende Prozeß muß dann vor seinem Eintritt prüfen, ob
der Bereich frei ist, die Sperrvariable auf 1 setzen und nach Ende wieder
freigeben.
Der Abschnitt von der Prüfung der Sperrvariablen bis zu ihrem Setzen
ist selbst ein kritischer Abschnitt! Er ist zwar kürzer und damit die
Konfliktwahrscheinlichkeit geringer, aber die Gefahr des Konfliktes ist nicht
beseitigt! Es gibt bei vielen CPUs jedoch Befehle von der Form "teste und setze",
bei denen der kritische Abschnitt innerhalb eines Maschinenbefehls "abgehandelt"
wird. Damit sind folgende Lösungen möglich:
- "Aktives Warten":
bool v;
/* Warteschleife, bis Riegelvariable RV[i]= 0 ist */
do
v = test_and_set(&RV[i]);
while (v == 0);
...
/* kritischer Abschnitt zur Datenmenge i */
...
RV[i] : = 1;
Die Ver- bzw. Entriegelung wird häufig mit den Funktionen LOCK und
UNLOCK formuliert:
L0CK(RV[i]);
...
/* kritischer Abschnitt zur Datenmenge i */
...
UNLOCK(RV[i]);
Viele Computer, die für Mehrprozessorbetrieb konzipiert wurden, kennen den
Maschinenbefehl "Test and Set Lock". Dabei wird ein Speicherwort aus einem
Register gelesen und ein Wert ungleich Null hineingeschrieben.
Für die TSL-Operation wird eine gemeinsame Variable namens "Flag" verwendet.
Diese koordiniert den Zugriff. Beispiel:
enter_region: tsl register,flag kopiere flag ins Register und setzte flag auf 1
cmp register,#0 war flag Null?
jnz enter_region wenn nicht, Verriegelung gesetzt, Schleife
... kritischer Bereich ...
leave_region: mov flag,#0 flag auf 0 setzten
ret Rückkehr zum Aufrufer
Aktives Warten verbraucht CPU-Zeit durch Warteschleifen.
- "Striktes Alternieren":
Nur zwei Prozesse erlauben sich wechselweise den Eintritt in den kritischen
Abschnitt mit einer logischen Sperrvariablen. Zum Beispiel dient die gemeinsame
Sperrvariable turn zur Synchronisiation zweier Prozesse. Es gilt:
turn = i (i = 0,1) --> Prozeß Pi darf in den
kritischen Bereich eintreten:
PO:
while (1)
{
while (turn != 0) no_operaion; /* warten */
kritischer Bereich;
turn = 1;
unkritischer Bereich;
}
P1:
while (1)
{
while (turn != 1) no_operaion; /* warten */
kritischer Bereich;
turn = 0;
unkritischer Bereich;
}
Auch hier wird CPU-Zeit durch Warteschleifen verbraucht. Außerdem
ist striktes Alternieren auch keine gute Lösung, wenn ein Prozeß
wesentlich langsamer ist als der andere.
- Semaphore
Bisher haben die Prozesse ihren Eintritt in den kritischen Abschnitt selbst gesteuert.
Die folgenden Techniken erlauben es dem Betriebssystem, Prozessen den Zutritt zum
kritischen Abschnitt zu verwehren. Im Zusammenhang mit Algol 68 entwickelte Dijkstra
das Prinzip der Arbeit mit Semaphoren. Für jede zu schützende Datenmenge
wird eine Variable (Semaphor) eingeführt (binäre Variable oder nicht-negativer
Zähler).
Ein Semaphor (Sperrvariable, Steuervariable) signalisiert einen Zustand (Belegungszustand,
Eintritt eines Ereignisses) und gibt in Abhängigkeit von diesem Zustand den weiteren
Prozeßablauf frei oder versetzt den betreffenden Prozeß in den Wartezustand.
Beim Bemühen um unteilbare Ressourcen (z. B. den Prozessor) wird eine binäre
Variable verwendet, bei N Teil-Ressourcen (z. B. Arbeitsspeicher-Segmente oder
Plätze in einem Puffer) kommen Werte von 1 bis N vor.
Die binären Semaphore werden auch "Mutexe" (von "Mutual exclusion") genannt,
jene vom Typ Integer auch "Zähl-Semaphore".
Semaphore für den gegenseitigen Ausschluß sind dem jeweiligen exklusiv
nutzbaren Betriebsmittel zugeordnet und verwalten eine Warteliste für dieses
Betriebsmittel. Sie sind allen Prozessen zugänglich. Semaphore für die
Ereignissynchronisation zweier voneinander datenabhängiger Prozesse sind diesen
Prozessen direkt zugeordnet. Sie dienen zur Übergabe einer Meldung über das
Ereignis zwischen den Prozessen.
Zur Manipulation und Abfrage von Semaphoren existieren zwei unteilbare, d. h. nicht
unterbrechbare Operationen (Semaphor S):
- P-Operation: Anfrage-Operation
if (s > 0)
s = s - l; /* Prozeß kann weiterlaufen,
Zugriff für andere Prozesse wird gesperrt */
else
/* der die P-Operation ausführende Prozeß wird "wartend";
Eintrag des Prozesses in die vom Semaphor
verwaltete Warteliste; */
- V-Operation: Freigabe-Operation
if (Warteliste leer)
s = s + l; /* Zugriff für andere, noch nicht wartende
Prozesse wird freigegeben */
else
/* nächster Prozeß in Warteliste wird "bereit";
Zugriff für wartenden Prozeß wird freigegeben */
Lösungsmöglichkeit für Erzeuger-Verbraucher-Synchronisation
(Vorbesetzung der Semaphore: start = 0; finish = 0):
| Produzent: | | Konsument: |
|---|
while (1)
{
while (!buffer-full)
write_into_buffer();
signal(start); /* V-Operation */
wait(finish); /* P-Operation */
}
|
|
while (1)
{
wait(start); /* P-Operation */
while(!buffer-empty)
read_from_buffer();
signal(finish); /* V-Operation */
}
|
- Ereigniszähler
Für einen Ereigniszähler E sind drei Operationen definiert:
- read(E): Stelle Wert von E fest!
- advance(E): Inkrementiere E (atomare Operation)
- await(E,v): Warte bis E = v ist
Damit kann E nur wachsen, nicht kleiner werden! E sollte mit 0 initialisiert werden.
Die hier gezeigte Produzent-Konsument Lösung verwendet die Operation read()
nicht, andere Sychronisationsprobleme machen diese Operation dennoch notwendig.
Hier arbeitet der Puffer als Ringpuffer.
Anmerkung: Mit % wird der Modulo-Operator gekennzeichnet (= Rest der ganzzahligen
Division).
#define N 100 /* Puffergröße */
eventcounter inputcounter = 0, outputcounter = 0; /* Ereigniszaehler */
int inputsequence = 0, outputsequence = 0;
producer()
{
tinhalt item;
while (1)
{
produce(&item);
inputsequence = inputsequence + 1;
await(outputcounter,inputsequence-slots);
buffer[(inputsequence - 1) % N] = item;
advance(inputcounter);
}
}
consumer()
{
tinhalt item;
while (1)
{
outputsequence = outputsequence + 1;
await(inputcounter,outputsequence);
item = buffer[(outputsequence - 1] % N);
advance(outputcounter);
consume(&item);
}
}
Die Ereignis-Zähler werden nur erhöht, nie erniedrigt. Sie
beginnen immer bei 0. In unserem Beispiel werden zwei
Ereignis-Zähler verwendet. inputcounter zählt die
Anzahl der produzierten Elemente seit dem Start. outputcounter
zählt die Anzahl der konsumierten Elemente seit dem Start. Aus diesem
Grunde muß immer gelten: outputcounter <= inputcounter.
Sobald der Produzent ein neues Element erzeugt hat, prüft er mit Hilfe
des er den await-Systemaufrufs, ob noch Platz im Puffer vorhanden
ist. Zu Beginn ist outputcounter = 0 und (inputsequence - N)
negativ - somit wird der Produzent nicht blockiert. Falls es dem Produzenten
gelingt N+1 Elemente zu erzeugen, bevor der Konsument startet, muß er
warten, bis outputcounter = 1 ist. Dies tritt ein, wenn der Verbraucher
ein Element konsumiert. Die Logik des Konsumenten ist noch einfacher. Bevor das m-te
Element konsumiert werden kann, muß mit await(inputcounter,n)
auf das Erzeugen des m-ten Elementes gewartet werden.
Auf die Probleme, die bei der Konkurrenz von Prozessen um exklusiv nutzbare
Betriebsmittel auftreten, wird in Kapitel 4.5
eingegangen.
2.6 Prozeß-Kommunikation
Bei Multitasking-Betriebssystemen spielt die Kommunikation bzw. Synchronisation zwischen
den quasiparallel ablaufenden Prozessen eine herausragende Rolle. Die Gründe dafür
sind vielfältig. Zum einen werden größere Softwaresysteme häufig als
Systeme mit mehreren kooperierenden Prozessen gestaltet. Diese müssen normalerweise in
ihren Abläufen synchronisiert werden. Ferner müssen häufig Daten von einem
Prozeß zum anderen transferiert werden. Ein anderer Grund liegt im Problem der
kritischen Abschnitte von Prozessen beim Zugriff auf nicht gemeinsam benutzbare
Betriebsmittel. Auch hier sind Synchronisationsmethoden erforderlich, die den gegenseitigen
Ausschluß gewährleisten (siehe oben: Semaphore). Einige Möglichkeiten
der Prozeß-Kommunikation (Interprocess Communication (IPC) sind:
- Kommunikation über gemeinsame Speicherbereiche
Prozesse können gemeinsame Datenbereiche, Variablen etc. anlegen und
gemeinsam nutzen.
- Kommunikation über gemeinsame Dateien
Prozesse schreiben in Dateien, die von anderen Prozessen gelesen werden.
- Kommunikation über Pipes
Dies sind unidirektionale Datenkanäle zwischen zwei Prozessen.
Ein Prozeß schreibt Daten in den Kanal (Anfügen am Ende)
und ein anderer Prozeß liest die Daten in der gleichen Reihenfolge
wieder aus (Entnahme am Anfang). Realisierung im Speicher oder
als Dateien. Lebensdauer in der Regel solange beide Prozesse existieren.
- Kommunikation über Signale
Signale sind asynchron auftretende Ereignisse, die eine Unterbrechung bewirken
(--> Software Interrupt). In der Regel zur Kommunikation zwischen BS und
Benutzerprozeß.
- Auslösung vom Benutzer (z.B. Tastendruck)
- Auslösung durch Programmfehler (z.B. Division durch 0)
- Auslösung durch andere Prozesse (z.B. Plattenzugriff
durch BS-Dienstroutine, "Daten sind bereit")
- ...
- Kommunikation über Nachrichten (Botschaften, Messages)
Nachrichten werden vom BS verwaltet. Dieses stellt eine für die beteiligten
Prozesse gemeinsam nutzbare Transportinstanz (z. B. "Mailbox") zur Verfügung.
Auf diese greifen die Prozesse über bestimmte Transport-Funktionen des BS
(Systemaufrufe) zu. Prozeß A sendet z. B. eine Botschaft
an Prozeß B, indem er sie in der Mailbox ablegt (send(message);).
Der Prozeß B holt die Nachricht dann von der Mailbox ab (receive(message);).
- Kommunikation über Streams
Streams ermöglichen die Kommunikation über Rechnernetze.
Logisch gesehen haben Streams dieselbe Aufgabe wie die lokalen Pipes.
- Kommunikation über Prozedurfernaufrufe (remote procedure call)
Ein Prozeß ruft eine in einem anderen Prozeß angesiedelte Prozedur auf
(also über seine Adreßgrenzen hinweg). Besonders für Client-Server-Beziehungen
geeignet.
Selbst bei sehr einfachen Betriebssystemen ist eine IPC notwendig, da zumindest
eine Kommunikation zwischen einem Prozeß und dem Scheduler möglich sein
muß.
2.7 Prozeß-Scheduling
In Multitasking-Betriebssystemen ist ein spezieller Prozeß notwendig, der
aus den bereiten Prozessen den nächsten aktiven Prozeß auswählt.
Sobald mehr als ein Prozeß den Zustand "bereit" besitzt, muß
der Scheduler des Betriebssystems entscheiden, welcher Prozeß die CPU
erhält (wir gehen zur Vereinfachung von einem System mit nur einem Prozessor aus).
Kriterien für einen guten Scheduler sind:
- Gerechtigkeit: Jeder Prozeß erhält einen "gerechten" CPU-Anteil
- Effizienz: Die CPU sollte immer zu 100% ausgelastet sein
- Antwortzeit: Minimale Antwortzeit für interaktive Benutzer
- Verweilzeit: Angemessen kurze Verweilzeit für Batch-Aufträge
- Durchsatz: Möglichst viele Aufträge/Zeitraum abarbeiten
- Terminerfüllung: Bereitstellung bestimmter Ergebnisse zu festgelegten Zeitpunkten
Bei Multitasking-Betriebssystemen werden zwei Grundsysteme für das Scheduling
unterschieden:
- kooperatives Multitasking (non preemptive)
Der aktive Prozeß gibt von sich aus die CPU zu einem geeigneten Zeitpunkt
frei. Es ist nur ein geringer Verwaltungsaufwand nötig. Es besteht jedoch
die Gefahr, daß ein "unkooperativer" oder fehlerhafter Prozeß
alle anderen Prozesse blockiert.
- verdrängendes Multitasking (preemptive)
Der Scheduler kann einem Prozeß die CPU entziehen (z. B. ausgelöst durch
einen Timer-Interrupt). Dadurch kann die Bearbeitung dringlicherer Aufgaben jederzeit
begonnen werden (z. B. bei Echtzeit-BS). Ein fehlerhafter Prozeß kann das
System nicht blockieren.
Anstoß für den Prozeßwechsel durch Verdrängung:
- Zeitgesteuerte Strategien
Jeder Prozeß erhält die CPU für eine bestimmte Zeitspanne (Zeitscheibe).
Danach wird die CPU dem nächsten Prozeß zugeteilt (Zeitscheibenverfahren,
round robin).
- Ereignisgesteuerte Strategien
Ein Prozeßwechsel findet statt, wenn ein Ereignis (z. B. ein Hardwareinterrupt)
einen anderen Prozeß benötigt. Hier werden allgemein den einzelnen Prozessen
Prioritäten zugeordnet, die sich dynamisch ändern. Ein bestimmtes Ereignis
verleiht "seinem" Prozeß eine höhere Priorität.
Scheduling-Strategien
Bei kooperativem Multitasking oder ereignisgesteuerten Schedulern wird die Zuteilungsstrategie
über Prioritäten gesteuert, wobei man beim kooperativen System von relativem
Vorrang spricht (der erst nach Freigabe der CPU durch den aktiven Prozeß
wirksam wird) und beim ereignisgesteuerten System vom absoluten Vorrang (der sofort
zum Prozeßwechsel führt).
Die Zeitscheibensteuerung kann als Sonderfall der Ereignissteuerung betrachtet
werden, das Ereignis ist in diesem Fall der Ablauf der zugeteilten Zeitscheibe.
Einige Strategien, die in der Praxis verwendet werden, sind:
- Wer zuerst kommt, wird zuerst bedient (first come, first served):
Verteilung der Prioritäten nach Ankunftszeit, ohne Vorrechte. Kommen
zwei Prozesse genau gleichzeitig, wird eine zufällige Auswahl getroffen.
Gute Systemauslastung, aber schlechtes Antwortzeitverhalten (lang laufende Prozesse
behindern Kurzläufer). Einfach zu implementieren.
- Zeitscheibenverfahren (round robin):
Jeder Prozeß erhält eine feste Zeitspanne (time slice) zugeordnet.
Nach Ablauf dieser Zeitspanne wird er verdrängt und der nächste Prozeß
erhält die CPU --> zyklische Zuteilung. Alle Prozesse haben immer die gleiche
Priorität. Die Zeitspanne kann konstant sein oder abhängig von der
Prozessorbelastung variieren. Kurze Antwortzeiten bei kleinen Zeitscheiben,
aber dann höhere Verluste durch die häufigen Prozeßwechsel.
- Prioritätssteuerung:
Jedem bereiten Prozeß wird eine Priorität zugeordnet. Vergabe der CPU in absteigender
Priorität. Ein Prozeß niedrigerer Priorität kann die CPU erst erhalten, wenn alle
Prozesse höherer Priorität abgearbeitet sind. Ein bereit werdender Prozeß höherer
Priorität verdrängt einen aktiven Prozeß niedrigerer Priorität. Alle Prozesse
gleicher Priorität werden i.a. in jeweils einer eigenen Warteschlange geführt
Realisierung mehrerer unterschiedlicher Verfahren, z. Teil gemischt mit anderen
Strategien , z. B.
- Reine Prioritätssteuerung: Prozesse gleicher Priorität werden nach der
Eingangsreihenfolge abgearbeitet (z. B. in Echtzeit-BS)
- Prioritätsgesteuerung mit unterlagertem Zeitscheibenverfahren:
Prozesse gleicher Priorität werden nach dem Zeitscheibenverfahren abgearbeitet
- Dynamische Prioritätsvergabe:
Die Priorität auf die CPU wartender Prozesse wird allmählich erhöht
- Mehrstufiges Herabsetzen (multilevel feedback):
Festlegung einer maximalen Rechenzeit für jede Prioritätsstufe. Hat ein Prozeß
die max. Rechenzeit seiner Priorität verbraucht, bekommt er die nächstniedrigere
Priorität, bis er die niedrigste Stufe erreicht hat.
- Es gibt noch zahlreiche weitere Scheduling-Strategien.
In Dialogsystemen wird normalerweise Round Robin verwendet, um den Benutzern akzeptable
Antwortzeiten zu bieten. Bei Batchbetrieb und gemischten Systemen kommen oft Kombinationen
der o. g. Strategien vor - z. B. getrenntes Scheduling für Dialog- und Batchbetrieb.
2.8 Beispiele
- Windows bis Version 3.0
Jeder Prozeß erhält eine feste Zeitscheibe. Die Prozesse können untereinander
nicht kommunizieren (außer auf dem Umweg über das Betriebssystem). Ereignisse
(z. B. Mausbewegung) werden von Betriebssystem bearbeitet und den Prozessen gemeldet.
Eigentlich nur die Vorstufe eines Multitasking-BS --> Prozeß-Swapper.
- Windows ab Version 3.1
Kooperatives Multitasking. Ein Prozeß kann eine "öffentliche"
Nachrichten senden, die dann von einem anderen Prozeß aufgenommen und beantwortet
werden kann (Client-Server-Prinzip). Für Ereignisse (z. B. Mausbewegung) existieren
jeweils einzelne Prozesse. Der BS-Kern stellt nur eine Schnittstelle für Systemaufrufe
zur Verfügung.
- Windows NT/2000/XP
Prinzipielle Arbeitsweise wie bei Windows ab 3.1. Jedoch überwacht der BS-Kern
die Kommunikation der Prozesse und kann sie gegebenenfalls verhindern. Zur besseren
Kooperation können einzelne Programme in mehrere Prozesse aufgeteilt werden,,
die wieder untereinander kommunizieren ("Multithreading", das englische
Wort "Thread" bedeutet "Faden" - die Teilprozesse eines Programms
sind sozusagen über ihre Kommunikationsverbindung "aufgefädelt").
- Unix
Zeitscheibenverfahren mit Prioritätssteuerung. Diverse Möglichkeiten der
IPC. Der BS-Kern verarbeitet alle Ereignisse und "weckt" den Prozeß
auf, dem das Ereignis zugeordnet ist. Zeitscheiben sind je nach Bedarf unterschiedlich
lang. Je nach Variante von Unix gibt es auch Multithreading. Zusätzlich ist
ein Multiuserbetrieb möglich.
Realzeitbetriebssysteme arbeiten in der Regel mit Zeitscheibenverfahren, wobei
zusätzliche Bedingungen hinzukommen. Ereignisse (in der Regel Hardware- oder
Software-Interrupts) müssen innerhalb einer bestimmten Sollzeit bearbeitet
werden (Echtzeitbedingung). Daher findet sich hier häufig eine Aufteilung
der Programme in einzelne Threads (bei Realzeitbetriebssystemen auch oft "Task"
genannt).
Copyright © FH München, FB 04, Prof. Jürgen Plate
 Zum vorhergehenden Abschnitt
Zum vorhergehenden Abschnitt Zum Inhaltsverzeichnis
Zum Inhaltsverzeichnis Zum nächsten Abschnitt
Zum nächsten Abschnitt